0. 太长不看
【由 ChatGPT 4.0 进行总结, thanks to 章魚燒吃章魚】
文章探讨了使用 MariaDB Connector Java 2.X 版本连接 TiDB 6.5+ 时,
开启 JDBC 参数 useCompression 导致的 SQL 执行错误问题。原因是一个 bug 导致包头的 sequence number 错误增加,而 TiDB 对此检查严格,会报错。
通过比较和抓包诊断后,提出解决方案包括 TiDB 端放宽检查和 MariaDB 端修复 bug 。
1. 问题起源
某天摸鱼时刷 TiDB 社区 AskTUG, 发现了一个问题。
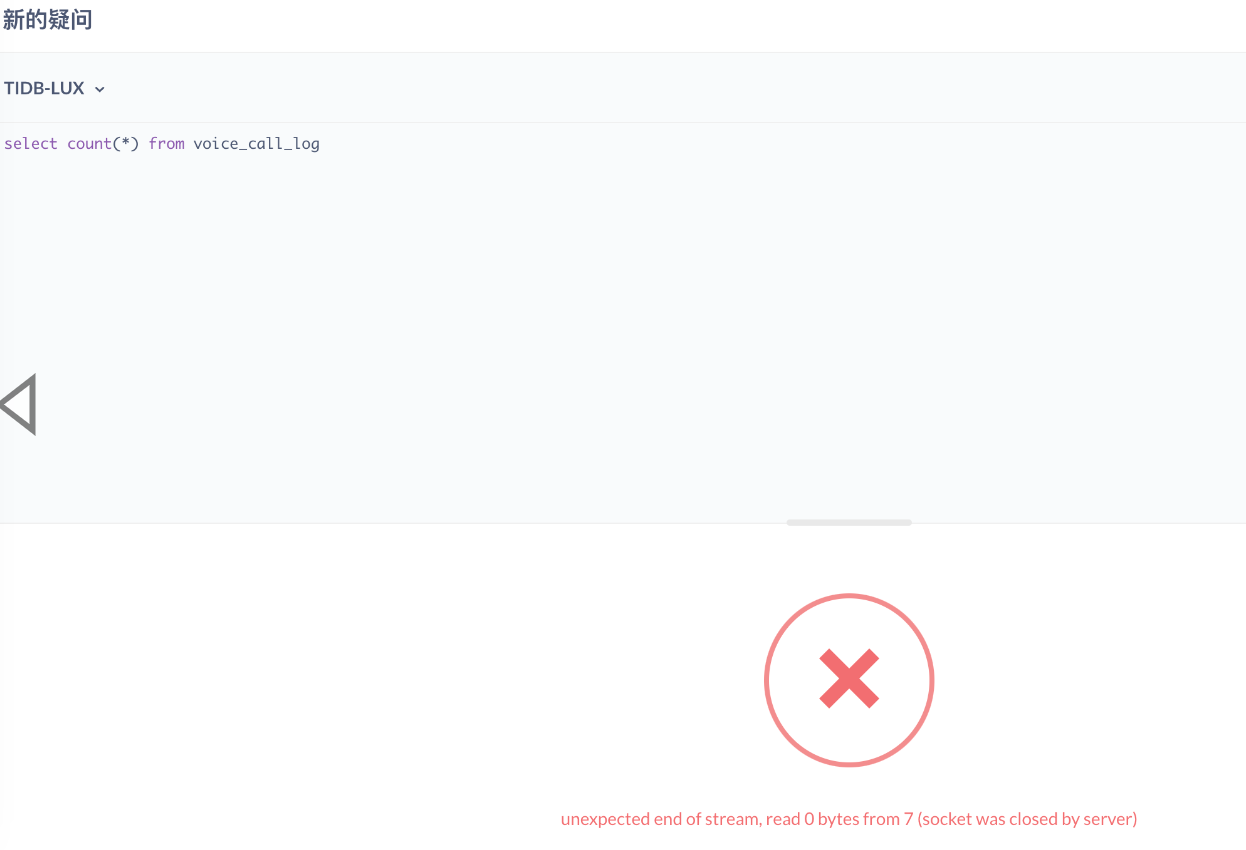
具体到JDBC, 报错如下:
unexpected end of stream, read 0 bytes from 7 (socket was closed by server)
很熟悉啊,一看大概就知道是网络相关的问题。特别是 7 个字节的读取。基于这点,大致能判断与 MySQL CS 协议相关,同时和 compress 有关系。搜了一下, Metabase 用 MySQL 的情况下没有这个问题,先把关键点锁定到 TiDB 上。
2. 现象查看
-
起一个 Metabase 和 TiDB, 跑了一下 select version(); 立刻就复现出来了。看一下 TiDB 的 log, 定位到了具体的代码。
sequence := header[3] if sequence != p.sequence { return nil, errInvalidSequence.GenWithStack("invalid sequence %d != %d", sequence, p.sequence) }通过报错信息能够很快拿到具体的 sql,但是中间加了一层 Metabase 有点扰乱思维,先拿到 JDBC 版本先。通过帖子中的描述,我们能很快知道应用用的是 MaraDB 的 JDBC,去 Github 上看看使用的版本。
先看语言,后端是 Clojure, 前端是 TS+JS, 那第三方依赖包就应该在 deps.edn 里头了。点进去直接搜索,果不其然,在 文件 中找到了使用的名称和版本,还贴心地解释了为啥卡死在 2.X。
;; The 3.X line of development for mariadb-java-client only supports the jdbc:mariadb protocol, so use 2.X for now. org.mariadb.jdbc/mariadb-java-client {:mvn/version "2.7.10"} ; MySQL/MariaDB driver之后就是尝试复现。开个 java 新项目,引用这个 jar 包,再跑下以下代码:
import java.sql.*; public class Main { public static void main(String[] args) { String url = "jdbc:mysql://127.0.0.1:4000/test?useCompression=True"; String user = "root"; String password = ""; try { Connection c = DriverManager.getConnection(url, user, password); Statement s = c.createStatement(); String sql = "-- :: userIDaebcda5cb52dc741f20fe495327ddbfc8411cc53663eec3a5ffdb1f30626d39cc606822\nselect version();"; s.execute(sql); s.close(); c.close(); } catch (SQLException e) { e.printStackTrace(); } } }成功复现!然后我们来看看这个问题是不是只在这个环境下出现。
把以上代码用以下环境分别匹配运行:
Client Server 结果 MySQL JDBC 8.X TiDB master 正常 MariaDB JDBC 2.X TiDB master 报错 MariaDB JDBC 3.X TiDB master 正常 MySQL JDBC 8.X MySQL 8 正常 MariaDB JDBC 2.X MySQL 8 正常 MariaDB JDBC 3.X MySQL 8 正常 现在问题已经锁定在了 MariaDB JDBC 2.X 和 TiDB 之间了。
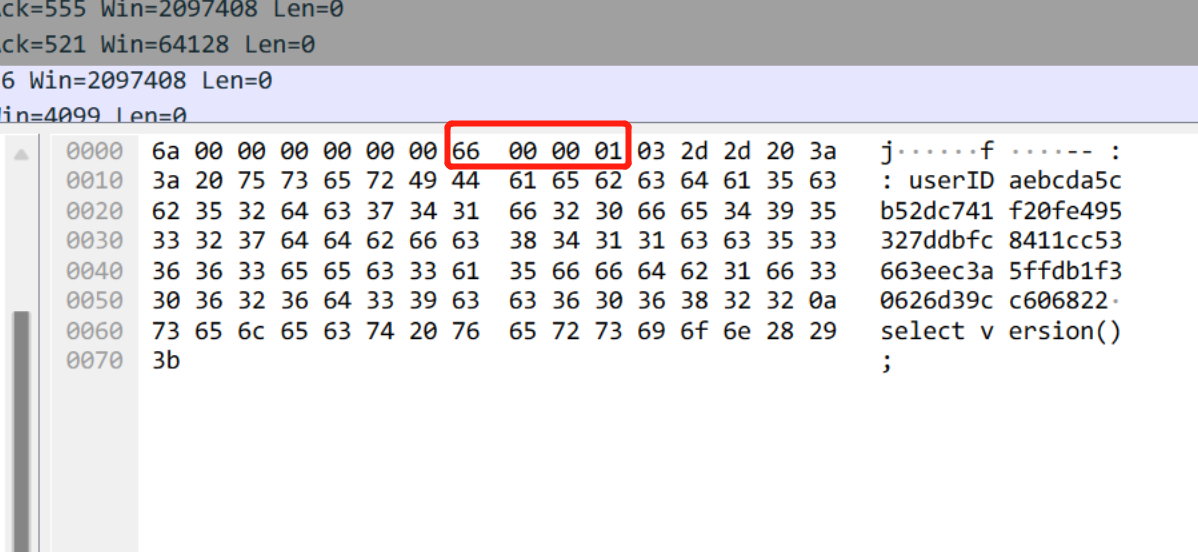
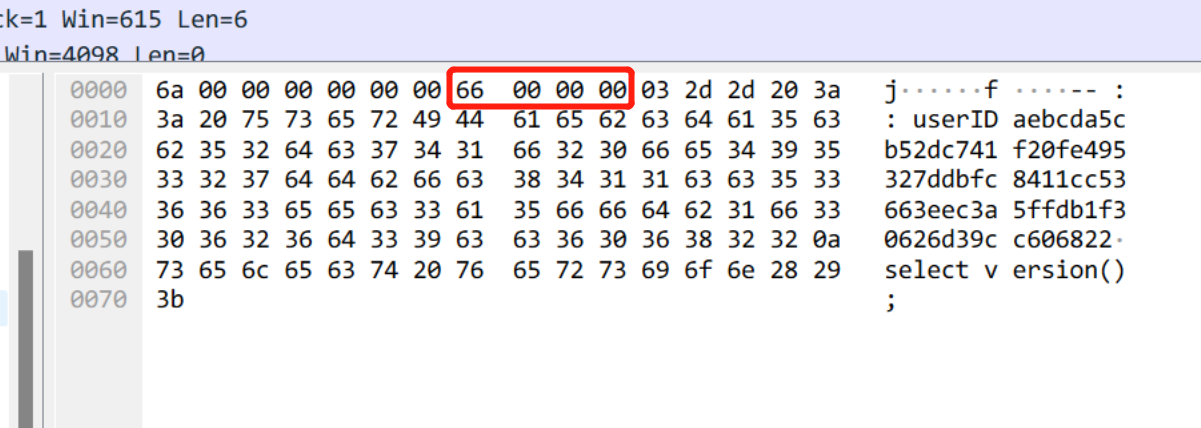
遇事不决先抓包。既然高版本能正常运行,抓 MariaDB JDBC 两个版本的包来对比看看。果然这一抓就发现问题了。
2.X
3.X
3. 整体梳理
以下内容需要对 MySQL 的协议包格式(header/compress header)有个基础的了解,可以参考着 MySQL 的 internal manual 看看。这里也有几篇不错的介绍基础知识的文章:
https://databaseblog.myname.nl/2023/11/notes-on-compression-in-mysql-protocol.html
https://www.cnblogs.com/lispking/p/3604063.html
简单来说(偷懒直接拿之后提交的 单元测试的注释 了):
// MySQL Compressed Protocol Header:
// 6a 00 00 Compressed length
// 00 Compressed Packetnr
// 00 00 00 Uncompressed length
//
// MySQL Protocol Header:
// 66 00 00 Payload length
// 01 Packet Sequence Number
// 03 COM_QUERY
// 2d 2d .. .. 3b SQL TEXT
需要说明的是,当 Uncompressed length 是 0 时,意味着之后的 payload 其实并没有压缩。很好理解,当 payload 过小时或者压缩收益不大时,不压缩是一个更好的选择。
整体概括一下,compress header 是正常的,0x03 和具体需要执行的 sql 也都正常。问题出在了 sub header 的 sequence number 上。正常情况下,这个值应该是 0x00,但是 2.X 版本的居然是 0x01 !
结合之前 TiDB 的报错信息来看,我们能判断出来 TiDB 的行为没错: 拿这个值和自身的 sequence number 比较,检测到不匹配后直接报错。
既然 TiDB 没错,那剩下的问题就是:
- 按照帖子的描述,为啥低版本 TiDB 不报错?
- 0x01 的 sequence number 是有问题的,为啥 MySQL 不报错?
- 这个 0x01 的 sequence number 是哪来的?
下面我们一个个定位。
4. 定位问题
-
TiDB 端 - 为啥低版本 TiDB 不报错呢?
通过 git blame 信息,这个问题很容易就能找到。TiDB 直到 这个时候 才开始支持协议端压缩。在之前,handshake 协商的时候就会回退到非压缩模式。非压缩模式不存在这个问题。这也就是帖子中提到的新版本 TiDB 报错的原因。
-
MySQL 端 - 为啥 MySQL 不报错?
就我目前来看,这是因为他们并没有认真对待这个 sequence number。从MySQL 8.2 版本的 源码 中来看,只检查compress sequence number 的正确性。
/* Verify packet serial number against the truncated packet counter. The local packet counter must be truncated since its not reset. */ if (pkt_nr != (uchar)net->pkt_nr) { /* Not a NET error on the client. XXX: why? */ #if !defined(MYSQL_SERVER) DBUG_PRINT("info", ("pkt_nr %u net->pkt_nr %u", pkt_nr, net->pkt_nr)); if (net->pkt_nr == 1) { assert(net->where_b == 0); /* Server may have sent an error before it received our new command. Perhaps due to wait_timeout. Only use what is already read and then close the socket. */ net->error = NET_ERROR_SOCKET_UNUSABLE; net->last_errno = ER_NET_PACKETS_OUT_OF_ORDER; net->pkt_nr = pkt_nr + 1;我感觉其实这倒是没啥问题。 个人觉得 sequence number 只是用来保障在不可靠的网络环境中正确的通信,而这个字段会出现问题,那只有可能在收发端。不过定义了不用,还是有点神奇。
-
MariaDB JDBC 端 - 0x01 是哪来的?
这其实才是今天这个问题的核心原因。大概翻了一下,问题出在 CompressPacketOutputStream.java 这个文件里头的 flushBuffer 函数。
if (pos > 0) { if (pos + remainingData.length > MIN_COMPRESSION_SIZE) { ............//省略 subHeader[0] = (byte) pos; subHeader[1] = (byte) (pos >>> 8); subHeader[2] = (byte) (pos >>> 16); subHeader[3] = (byte) this.seqNo++; deflater.write(subHeader, 0, 4); deflater.write(buf, 0, uncompressSize - (remainingData.length + 4)); deflater.finish(); } compressedBytes = baos.toByteArray(); if (compressedBytes.length < (int) (MIN_COMPRESSION_RATIO * pos)) { int compressedLength = compressedBytes.length; ............//省略 pos = 0; return; } } } ............//省略 // send packet without compression subHeader[0] = (byte) pos; subHeader[1] = (byte) (pos >>> 8); subHeader[2] = (byte) (pos >>> 16); subHeader[3] = (byte) this.seqNo++; out.write(subHeader, 0, 4); out.write(buf, 0, uncompressSize - (remainingData.length + 4)); cmdLength += remainingData.length; ............//省略原因其实显而易见了。这一块可以大概概括成以下步骤:
- 检测当前payload 长度是不是超过MIN_COMPRESSION_SIZE(100)。是的话去 2, 不是的话去 4.
- 生产 sub header,然后把这个包压缩一下。
- 如果压缩后的长度比 MIN_COMPRESSION_RATIO(0.9)小的话,就生产 header 然后返回,这时候传递的是压缩后的 payload。
- 不进行压缩,重新生成 header 和 sub header。然后传递没压缩过的 payload。
发现问题了么?当大于 100 的 payload 来到,但是因为压缩后效果又不明显,就会在 2 和 4 两步迎来两次 this.seqNo++ !在这种情况下 0x01 的 sequence number 也就被制造出来了。
5. 解决方案
问题明确了,解决方案也就出来了。
-
workaround
知道了是压缩协议实现的问题,那在 jdbc 层面禁用就好了,就和贴子里回复的一样。 -
TiDB 端
知道 MariaDB JDBC 有这个问题,放松一下这一块的检查。sequence := header[3] if sequence != p.sequence { err := server_err.ErrInvalidSequence.GenWithStack( "invalid sequence, received %d while expecting %d", sequence, p.sequence) if p.compressionAlgorithm == mysql.CompressionNone { return nil, err } // To be compatible with MariaDB Connector/J 2.x, // ignore sequence check and print a log when compression protocol is active. terror.Log(err) } -
MariaDB 端
修改一下流程,在这种情况下只 increase 一次。// ... private boolean subHeaderIsGenerated = false; protected void flushBuffer(boolean commandEnd) throws IOException { subHeader[1] = (byte) (pos >>> 8); subHeader[2] = (byte) (pos >>> 16); subHeader[3] = (byte) this.seqNo++; // ... subHeaderIsGenerated = true; protected void flushBuffer(boolean commandEnd) throws IOException { subHeader[0] = (byte) pos; subHeader[1] = (byte) (pos >>> 8); subHeader[2] = (byte) (pos >>> 16); // Avoid increasing the sequence of subHeader twice if (!subHeaderIsGenerated){ subHeader[3] = (byte) this.seqNo++; }6. 总结
- 使用 MariaDB Connecter Java (2.X) 连接 TiDB 高版本(6.5以上等), 在开启 JDBC 参数 useCompression 的情况下,执行特定 SQL 会报错。
-
原因在于 MariaDB CONJ 2.X 版本里头的一个 bug(CONJ-1145), 在特定情况下会导致包头 sequence number 额外增加 1。
同时相比于 MySQL / MariaDB, TiDB 对于 sequence 检查更为严格,在检测到这种情况下报错不再继续。 -
目前 MariaDB CONJ 的 bug 已经被确认,预计在 2.7.12 版本修正,修复patch 见链接。
同时提交了 PR 用于放松 TiDB 对于 sequence 的相关检查,目前已经合进了 master。