0. 太长不看
【由 ChatGPT 4.0 进行总结, thanks to 章魚燒吃章魚 提供】
这篇文章主要分析了 TDSQL 在版本升级过程中,由于时间精度同步错误而引发的时间精度原理。
文章讨论了使用 TiDB DM 进行跨系统数据同步的背景,以及在升级和同步过程中遇到的时间精度字段挑战,对数据迁移的影响。
文章深入探讨了 MySQL 和 MariaDB 版本对时间精度支持的演进,以及 binlog 中包含时间精度的解析原则,并提出了针对 TiDB DM 的优化策略,包括错误处理改进和同步任务的过滤机制。
在 TiDB DM 6.5 中已经基于该问题进行了优化, 参考 Changelog.
1. 背景
目前公司使用的 RDBMS 包括 TDSQL(based MariaDB) 和 TiDB。 在多数情况下, 需要 TiDB 官方提供的工具 DM(Data Migration) 做准实时的数据同步。这样可以实现在继续使用 TDSQL 的情况下解决单机容量、性能和多源汇聚的痛点。
最近有多个系统计划接入TiDB,并且对于 DM 有强需求,但是在接入过程中遇到了阻力:目前 DM 版本无法兼容以下场景:
- MariaDB 10.0.10 和从该版本原地升级到的 MariaDB 10.1.9 (参数 mysql56_temporal_format=OFF)。
- 存在时间精度的表有数据写入,即表含有时间精度格式字段(TIMESTAMP(N)、DATETIME(N) 、TIME(N))。
- 开启了 binlog 做主从复制。
在这种情况下, DM 的 worker 会直接 panic 并报 ”parse row events error“ 错误
目前临时的解决方案,是由应用层面做改造跑 alter table 把时间精度去掉,即 TIME(N) -> TIME.
但代价很高,一方面表结构变更引入变更风险或可能带来应用兼容性问题,另一方面工作量也很大, 涉及到不同业务的沟通协调。
具体到 DM, 本质就是伪装成 MySQL 的一个备库, 实时从 MariaDB 拉取 binlog 消费后再在 TiDB 回放,而 DM 拉取 binlog 的功能使用了第三方开源组件 go-mysql,一个实现了 mysql replication 协议的开源库。
因此在正式开始前, 我们需要对 MySQL 主从复制的协议有所了解。
2. Binlog 协议
以下内容涉及到 Binlog 协议的一些细节, 可以结合 MariaDB 的文档 稍微了解一下, 主要包含 Table Map Event 和 Write Rows Event v1。对于 Binlog 协议比较熟悉的话可以跳过这章。
因为问题涉及到存在时间精度的表有数据写入,整体流程用一个简单的例子来说明:
# 表结构:
create table test.tt(
ct timestamp(6) NOT NULL,
st varchar(30) default NULL,
st2 varchar(621) default NULL
) ENGINE = InnoDB CHARACTER SET = utf8;
# 重置 binlog 起始位置
reset master;
# 按下方 sql 生成的 binlog 举例
insert into test.tt values(
"2022-11-02 11:11:22.326147",
NULL,
NULL);
# 查看当前 binlog 状态
show binary logs;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000001 | 473 |
+------------------+-----------+
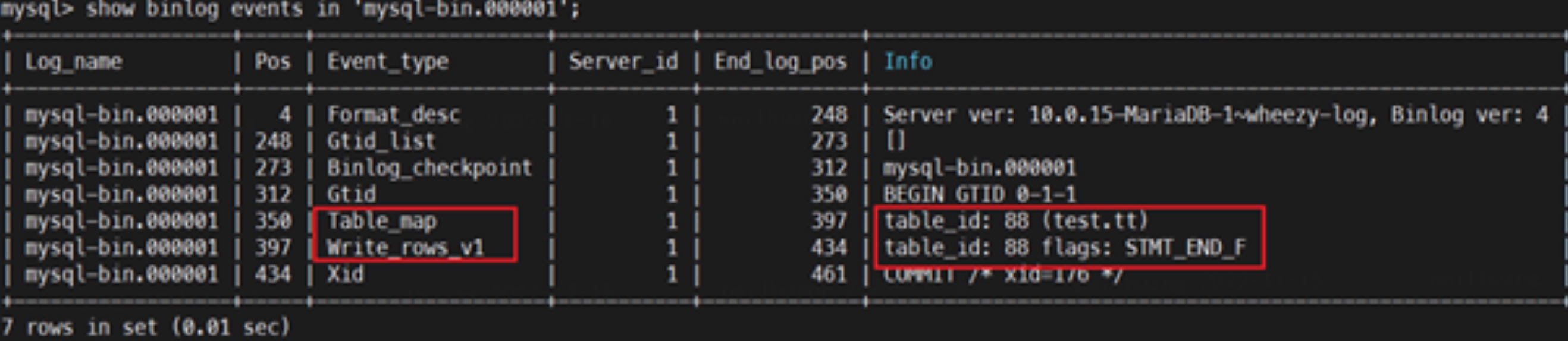
可以看出,对于row格式的DML操作而言,实际上在binlog里面记录的是:
Query : Begin
TableMap Event : 表映射关系
ROW_LOG_EVENT : WRITE/UPDATE/DELETE ROWS Event
Query/XId
结合 MariaDB 官方文档和部分解析教程,我们逐个字节解析了该 binlog 中涉及到的两个 event: Table Map Event 和 Write Rows Event v1.
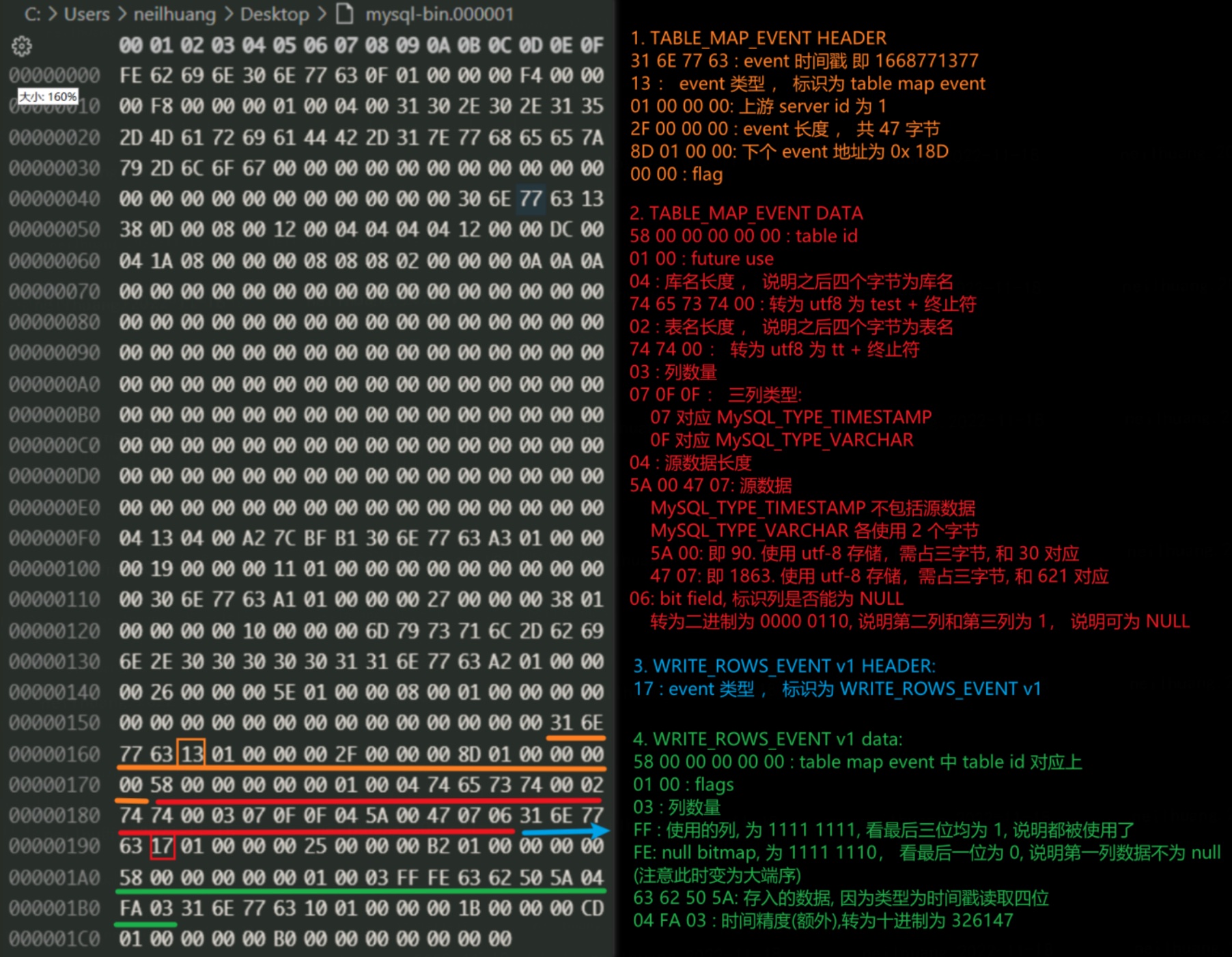
不难看出,其中 table_map event 记录的是表的元数据信息,例如库名、表名、字段类型等信息,而 WriteRowsEvent 则保存了 insert 的相关内容,包括插入的表和插入的数据。一个 insert 插入1条记录的 binlog,由 table_map+ write_rows 这2个 event 组成。
对同一个表的同一个事务操作,binlog只会记录了一个table_map用于记录表结构相关信息,而后面的 write rows 记录了更新数据的行信息。他们通过table_id来联系。【table_id在binlog内不是固定的,是一个变量,占用的是 table_definition_cache 和 table_open_cache 空间,因此 flush tables 会造成 table_id 的增长】
3. 定义问题
结合之前提到的TDSQL版本升级,引起了slave同步或DM同步的兼容性问题,总结成几个问题:
- MySQL/MariaDB 对于 时间精度特性 支持的版本发展历程,包括存储和 replication
- MySQL/MariaDB/DM 对于 含有时间精度 Binlog 的解析原理
- mysql56-temporal-format 参数的含义
带着这几个问题,我们继续深入。
4. 问题梳理
4.1 MySQL、MariaDB对于时间精度支持、兼容的发展时间线
MariaDB作为MySQL的重要分支,在早期有很多优秀特性都先于MySQL推出,比如并行复制,包括本文提到的时间精度等等。因此,之后我们整理了 MariaDB/MySQL 对于时间精度的支持的时间线,并以此来结合 MariaDB 的变化梳理了整体流程。
| 时间线 | MySQL | MariaDB | |
|---|---|---|---|
| 阶段一 | 不支持时间精度 | mysql 56 版本之前 | MariaDB 5.3 版本之前 |
| 阶段二 | MariaDB 5.3 支持时间精度 | / | MariaDB 5.3 版本支持时间精度 (复用 MYSQL_TYPE_* 时间类型) |
| 阶段三 | MySQL 56 支持时间精度 | mysql 56 版本支持时间精度 (引入了 MYSQL_TYPE_*2 类型) | 此时 MariaDB 5.3 无法从 mysql 56 同步包含时间精度的binlog event (MariaDB 不认识 MYSQL_TYPE_*2 时间类型) |
| 阶段四 | MariaDB 10.0.4 能够识别 MySQL 时间精度格式 | / | MariaDB 10.0.4 开始兼容 MYSQL_TYPE_*2 时间类型 (只在解析时使用,不用于自身存储表结构, 也不能产生相关类型的 binlog) |
| 阶段五 | MariaDB 10.1.2 原生支持设置 MySQL 时间精度格式为默认 | / | MariaDB 10.1.2 引入 mysql56_temporal_format 参数 为 ON 则在存储表结构时使用 MYSQL_TYPE_*2 时间类型 且产生的 binlog 在 TABLE MAP EVENT 中使用此时间类型 |
| 阶段六 | MariaDB 10.1.12 修复不同时间格式转换的问题 | / | MariaDB 10.1.12 修复 Bug: 从老版本向开了参数的新版本建表同步时会导致崩溃 |
4.2 初始阶段
在 MySQL 5.6 和 MariaDB 5.3 之前,双方均不支持时间精度的设置。
此时执行下列语句
# 表结构:
create table test.ttt(
ct timestamp
) ENGINE = InnoDB CHARACTER SET = utf8;
# 重置 binlog 起始位置
reset master;
# 按下方 sql 生成的 binlog 举例
insert into test.ttt values("2022-11-02 11:11:22");

4.3 MariaDB 5.3
参考官方 changlog,MariaDB 于 5.3 版本率先支持时间精度的设置,包括 TIME | DATETIME | TIMESTAMP 三种类型,之后这一特性便一直延续下来了。

MariaDB 对于该特性实现方式如下:
-
binlog 生产:
- TABLE_MAP_EVENT: 无变动,保持使用原先的时间类型
- WRITE_ROWS_EVENT: 原本时间数据最后附带上精度值,timestamp 改为大端序
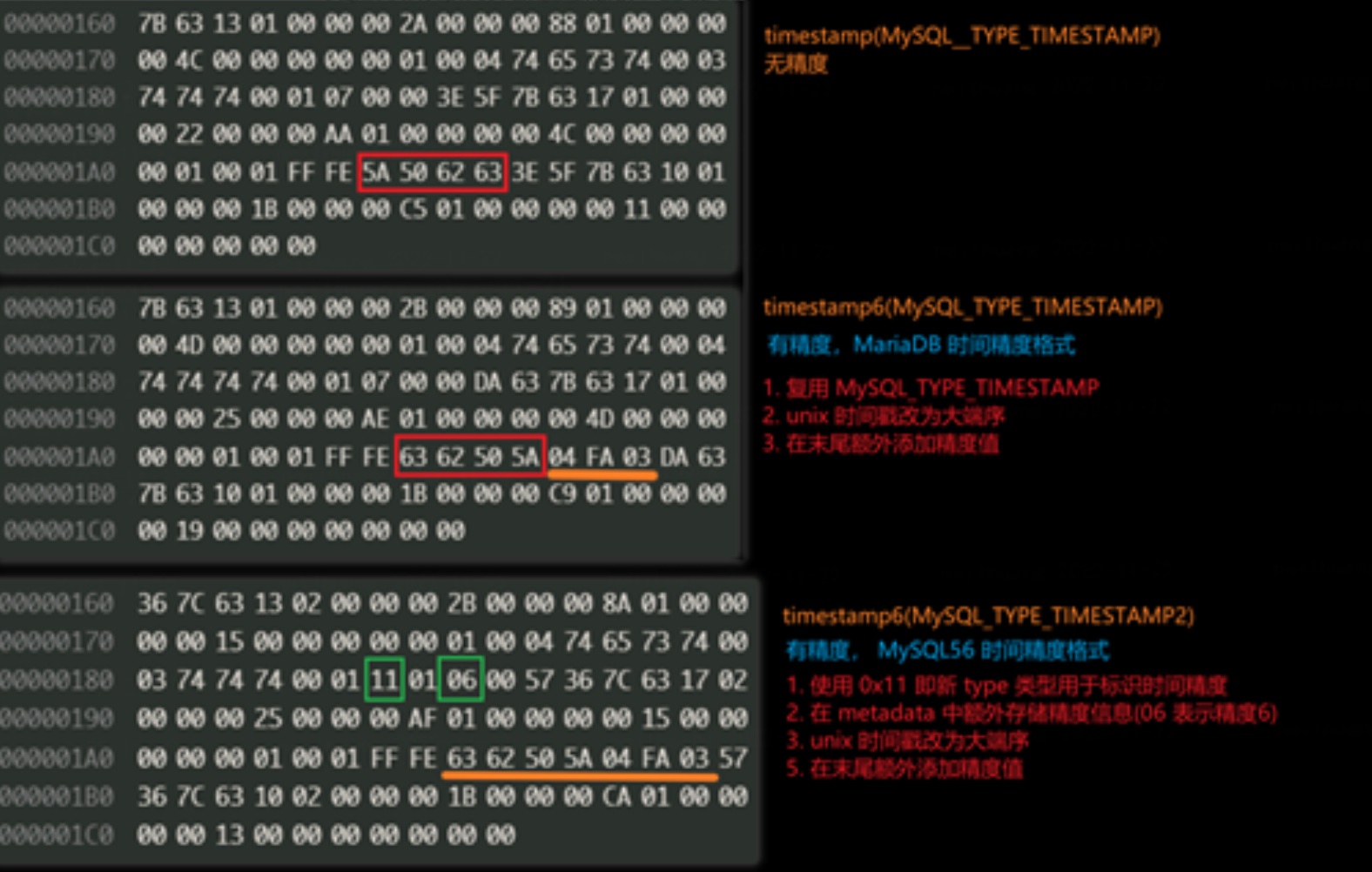
下图例子的列结构为 timestamp(6) ,63 62 50 DA 转为十进制解析得出 1667387610,时间戳转为时间为"2022-11-02 11:11:22",后六个字节为时间精度,即".326147"。
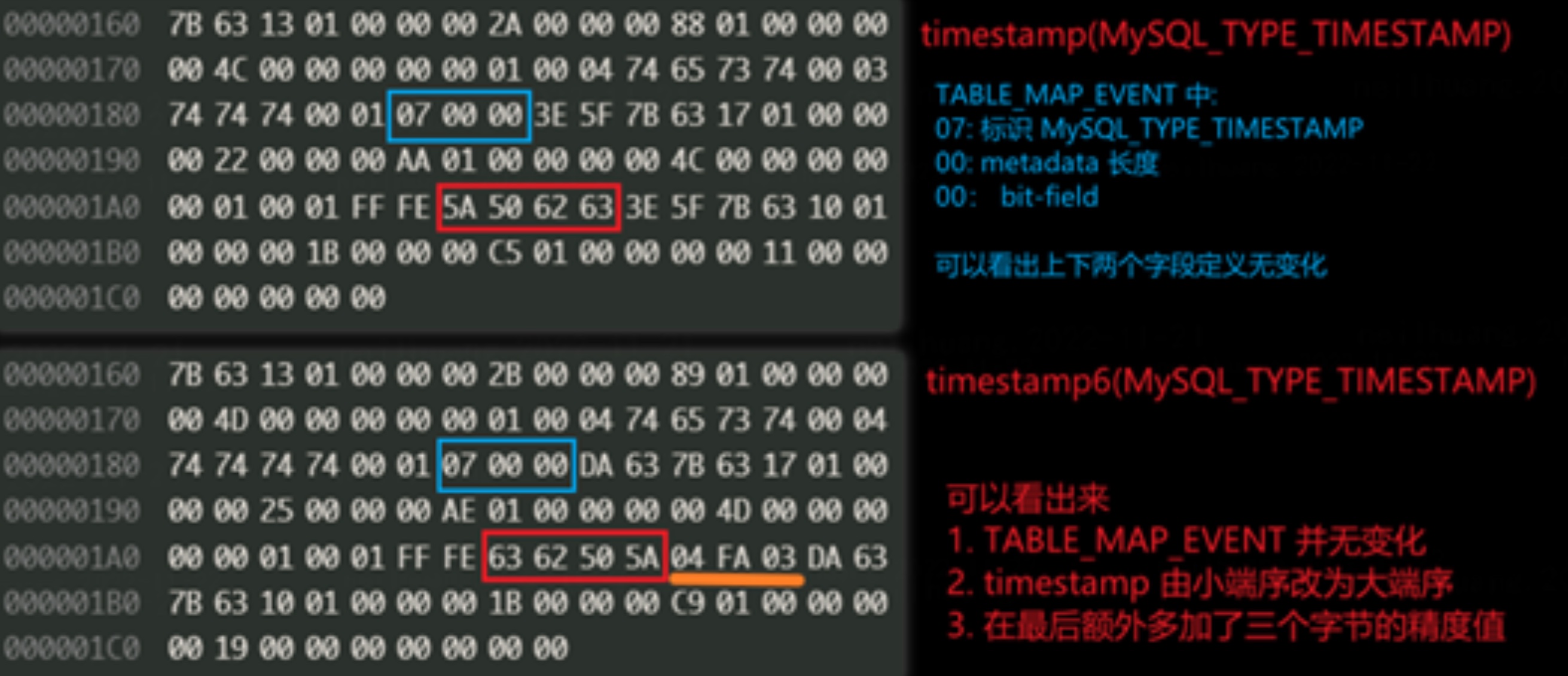
-
主备同步 binlog 解析:
- 参考代码,首先在构建字段时,会调用 calc_pack_length 根据不同类型从 frm 中拿到精度,在该函数中,我们可以看到,基于字段长度拿到对应的精度数值。

- frm 存储了表结构信息,每当创建一个表时,MySQL 会生成与之对应的 frm 文件。
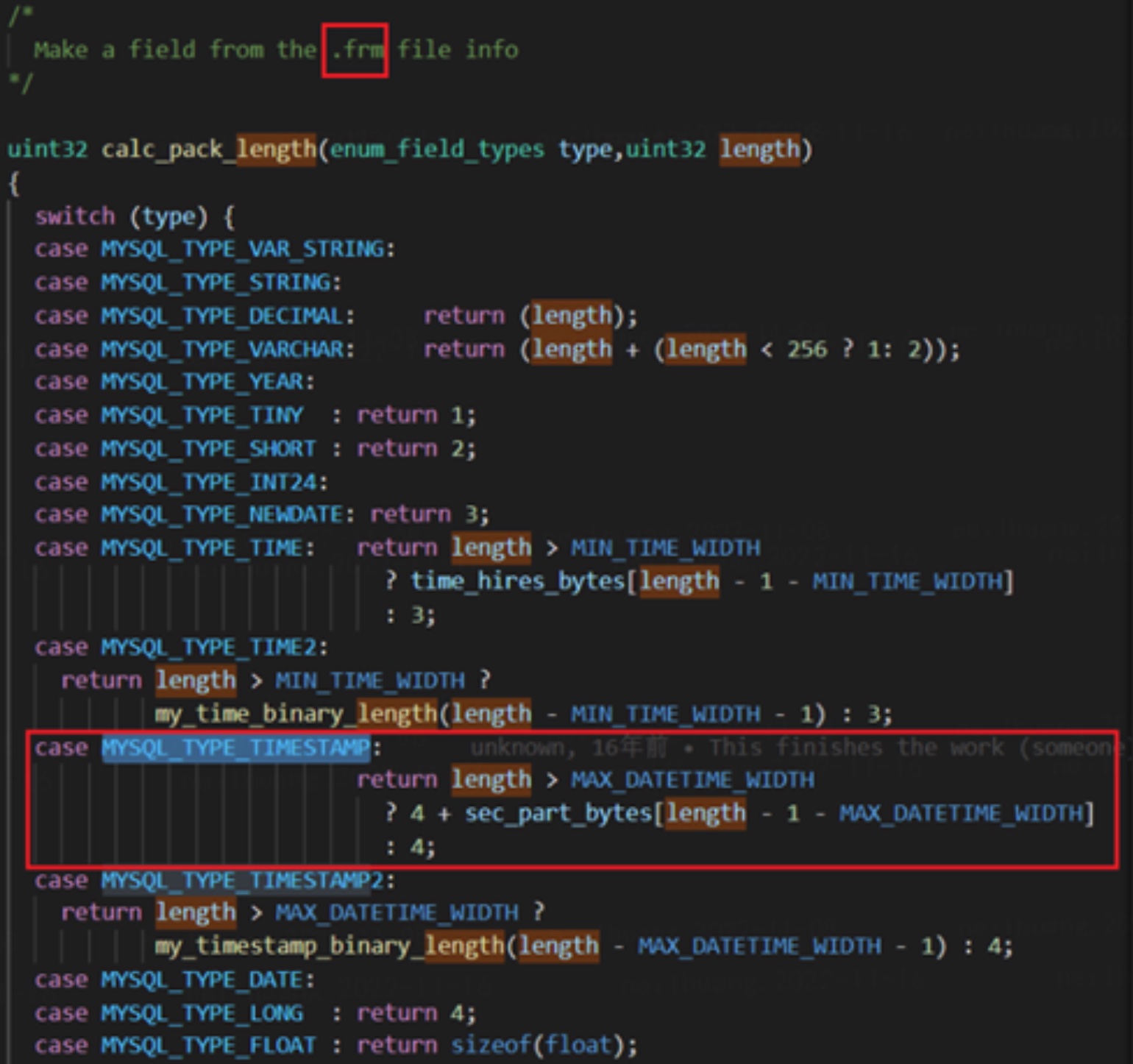
- 参考代码,首先在构建字段时,会调用 calc_pack_length 根据不同类型从 frm 中拿到精度,在该函数中,我们可以看到,基于字段长度拿到对应的精度数值。
- 当真实解析 binlog 时,会在 unpack_row 中调用当前字段类型 Field_timestamp_with_hires (继承于 Field_timestamp_with_dec) 的sec_part_bytes 方法获取当前的需要额外读取的字节数。
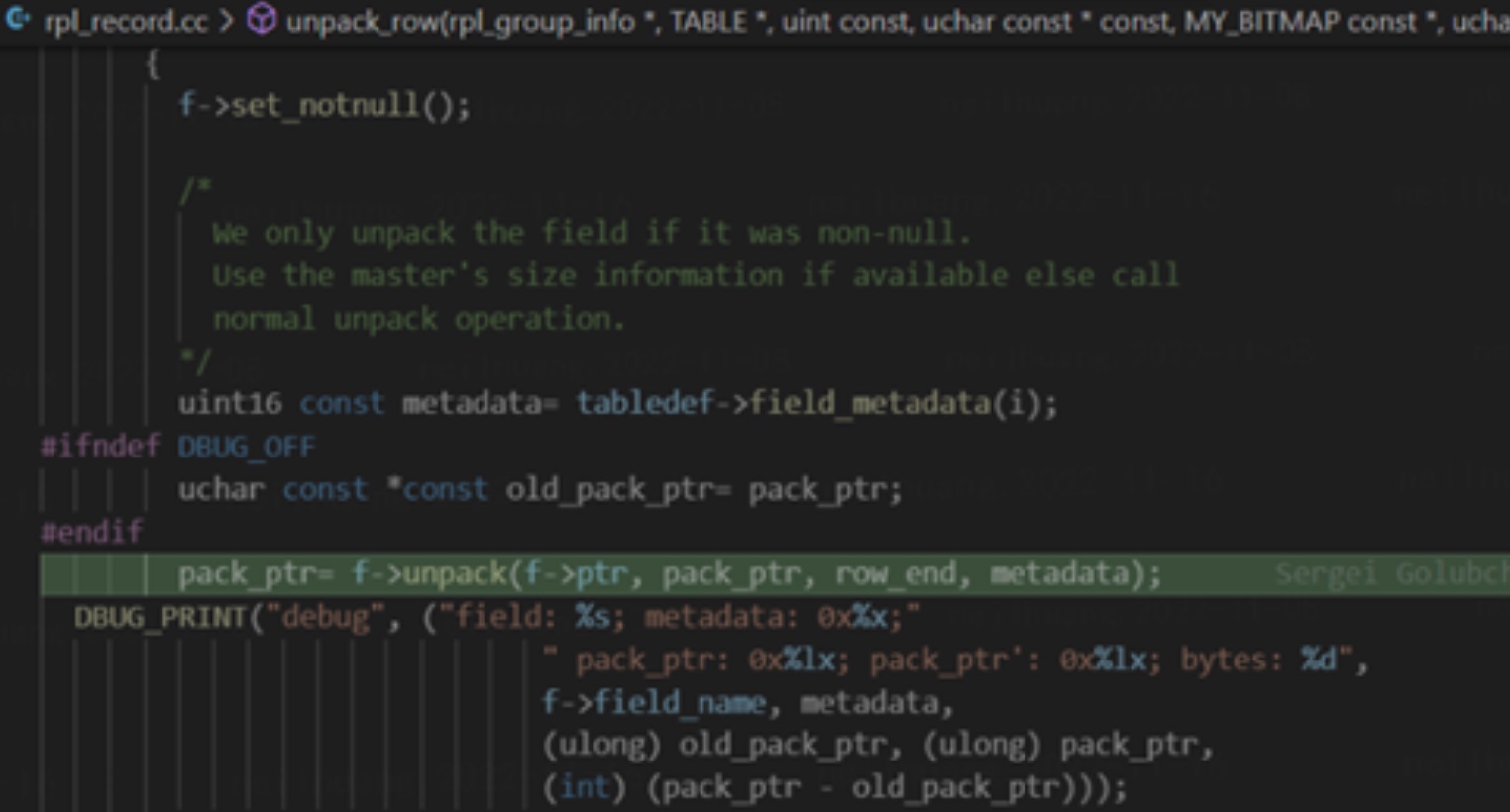
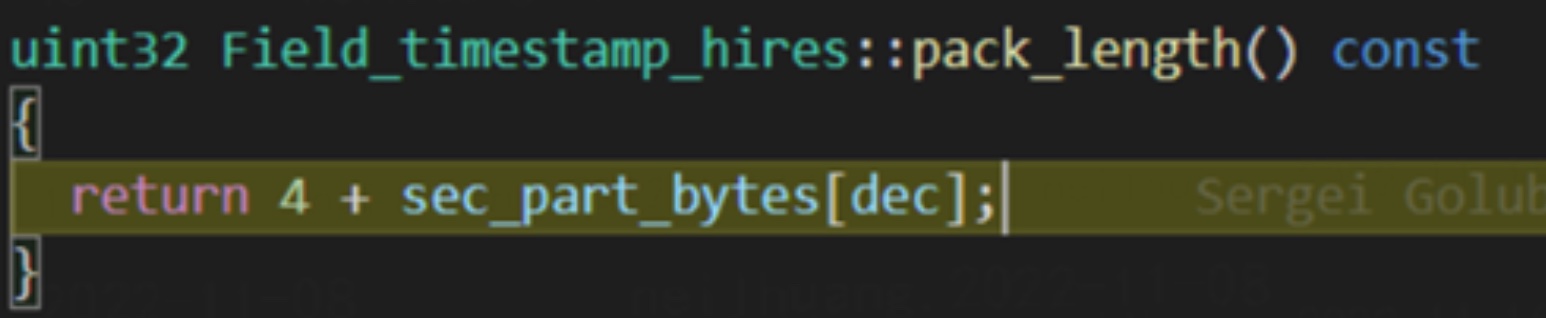
- 该实现主要依赖于本地的 frm 文件中的表结构,但过于草率的修改导致了以下问题:
- 绝大多数第三方binlog解析库对于表结构是不知情的。
这时候,因为 table_map_event 中并没有变化,第三方库会按照旧模式运作。但在列数据中却突然多了精度数据,因此第三方库会将其当成第二列去解析,错位导致第三方库以为数据缺失而最终报错。 MDEV-12744
同时在极端情况下,额外的数据正好能够填满一列,此时解析能够正常进行,但会导致错误数据产生。 - MariaDB 主备同步异常
若上下游表结构不一致,如上游是 TIME(2) 下游是 TIME(3) 。此时下游依赖本地表结构进行解析,也会导致错位报错或解析出错误数据。MDEV-5377 - 从 MariaDB 同步数据到 MySQL 或相反会导致报错。MDEV-6389
4.4 MySQL 5.6.4
基于此,MySQL 5.6 版本吸取了以上的经验,完善了对于时间精度的支持,主要变动:
- TABLE_MAP_EVENT
添加了版本2的时间类型专门用于标识带精度的时间类型,如 MYSQL_TYPE_TIME2 ,和原先的 MYSQL_TYPE_TIME 区分。并在 metadata 一列中添加了时间精度,确保不需要依赖外部的信息也能解析 binlog。
- WRITE_ROWS_EVENT:
优化了时间存储方式,支持了精度和负数,但代价是占用了更多的存储空间。
需要额外注意的是,TYPE2 的格式中的数据需要用大端序的方式解析,而非之前MySQL 一贯的小端序。

同理结合实际例子,相比于 MariaDB 的时间精度实现,MySQL56 的时间精度实现具体变化在 TABLE_MAP_EVENT 中:
- 额外规定了三个新类型用于标识带有时间精度的 binlog 类型,包括 MySQL_TYPE_TIMESTAMP2, MySQL_TYPE_TIME2 和MySQL_TYPE_DATETIME2, 用于和之前的时间类型区分。
- 在源数据一列中,添加了对应列的时间精度值,用于正常解析。
4.5 MariaDB 10.0.4
考虑到 MySQL 格式的兼容性更好,MariaDB 也于 10.0.4 提交了对于 MySQL 时间格式的支持。从该版本开始, MariaDB 能够识别 TYPE_*2 类型的列格式,并能够按照对应方法进行隐式判断和转换。(对应 commit)
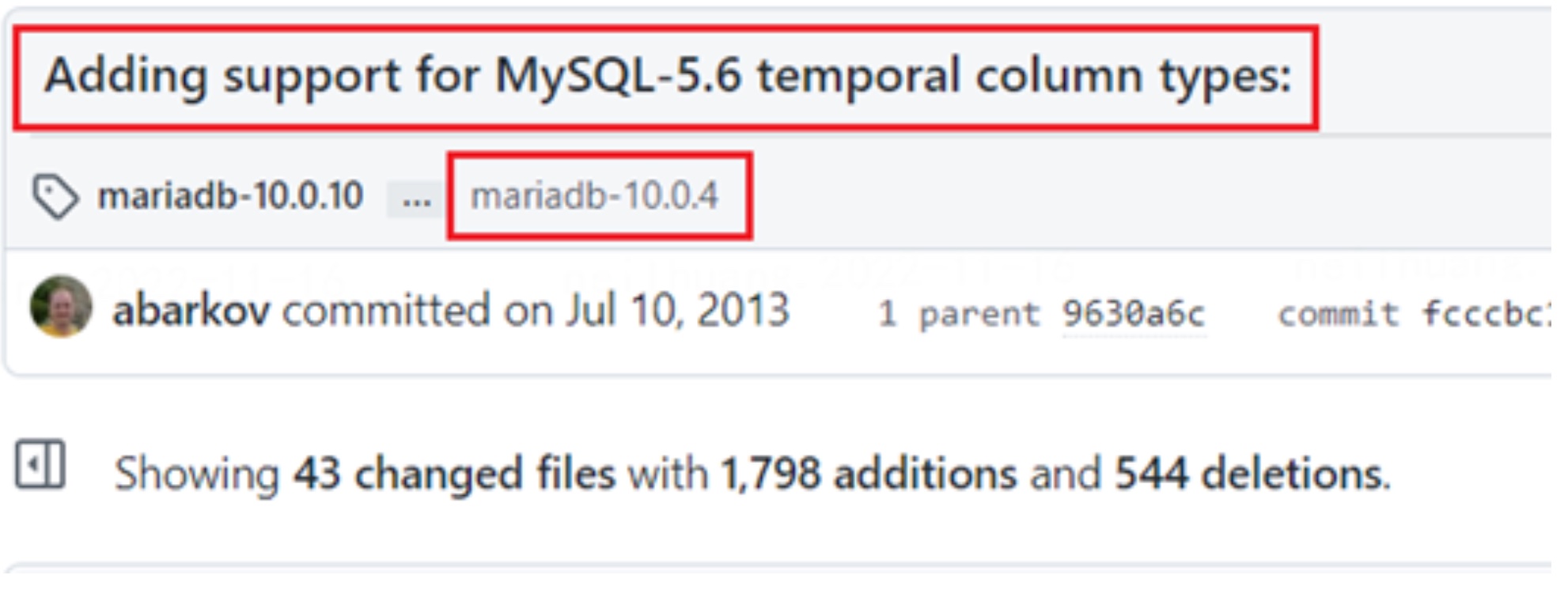
commit 的核心变动在 rpl_utility.cc 中的 can_convert_field_to 函数里,添加了一部分判断。field 来源于本地的表结构,source_type 则来自于 binlog 中的 MAP_TABLE_EVENT。
can_convert_field_to 来源于一个提案:WL#5151。当上下游类型有版本差异时,则会返回 -1, 标识于这两个字段能够互相转换。并在之后消费 binlog 时额外操作。(此时操作仍然存在问题,会在后头提到)
在该版本中, MariaDB 已经认识 MySQL5.6 的时间精度的格式并能正常消费了。但此时,本地的表结构和生产的 binlog 依旧是 MariaDB 的时间精度格式,对于主备同步和binlog解析并没有完全解决问题。
4.6 MariaDB 10.1.2
考虑到该情况, MariaDB 于 10.1.2 额外添加了一个命令行参数,叫 mysql56-temporal_format, 用来在底层存储和 binlog 生成层面指定具体的格式。

具体提交的 commit ,相关 issue: MDEV-5528
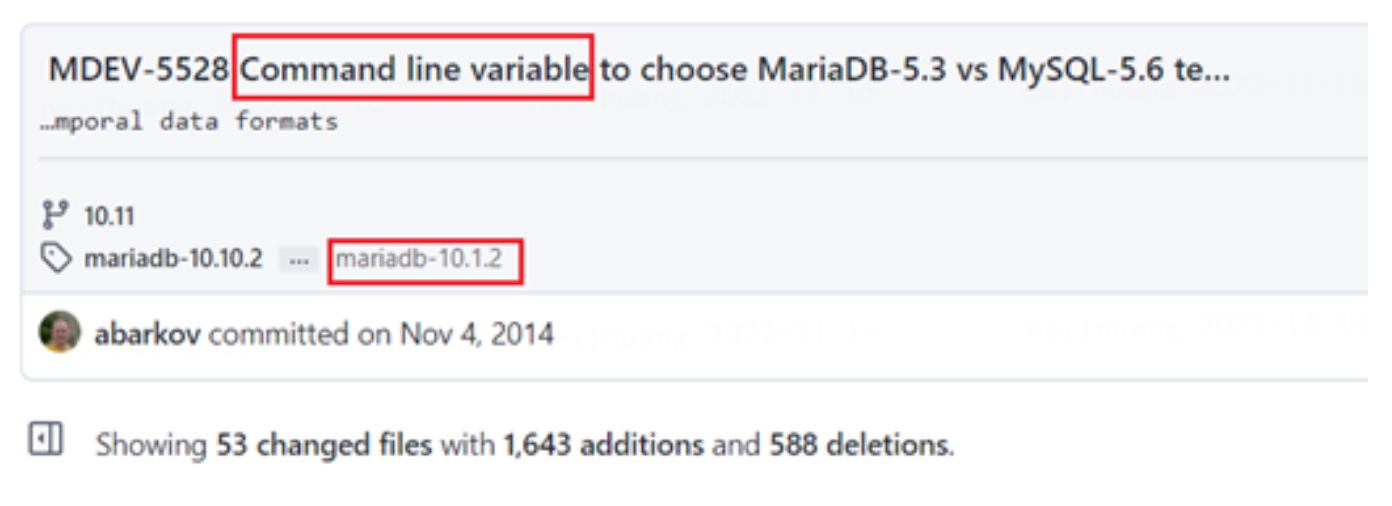
核心的变动在 Parser 层,即从 sql 语句解析为 AST 语法树层面。此时会额外判断该变量,若为真则为该列指定 TYPE2 的新格式。该变化会影响到底层表结构存储(frm) 和 binlog 的生成类型。
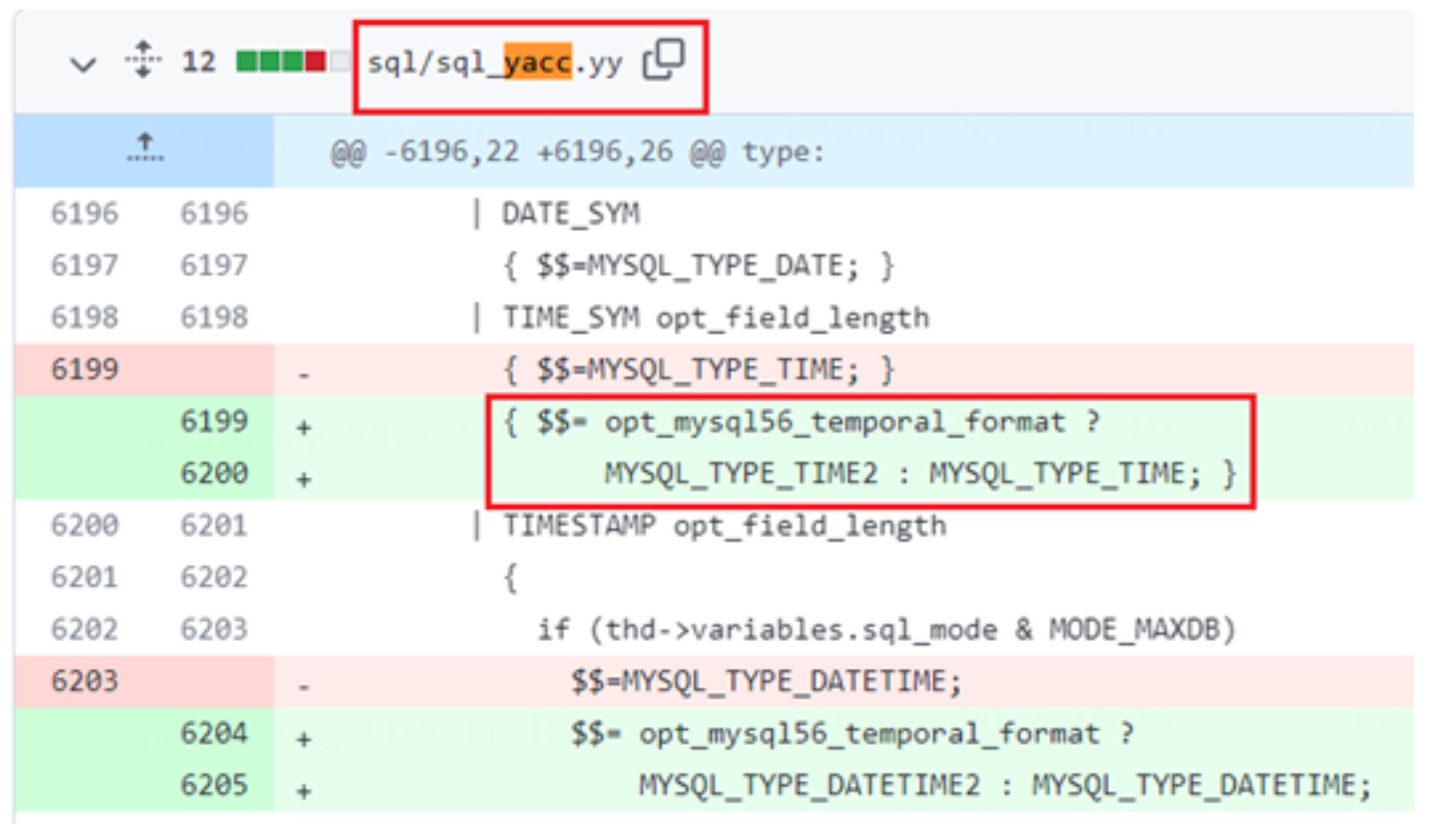
因此,我们判断,若是开启该参数,则新建表的底层存储及新表生成的 binlog 会变为MySQL 56 的时间格式,但并不会影响旧的表。之后我们基于此做了测试,符合推论。
| 建表时参数 | 插入时参数 | 本地表精度格式 | 生成 binlog 精度格式 |
|---|---|---|---|
| OFF | OFF | MariaDB | MariaDB |
| OFF | ON | MariaDB | MariaDB |
| ON | OFF | MySQL | MySQL |
| ON | ON | MySQL | MySQL |
4.7 MariaDB 10.1.12
基于 10.0.4 支持对 MySQL 精度格式的解析,和 10.1.2 支持对 MySQL 精度格式的生产(变量设置), 目前 MariaDB 应该可以做到完美支持 MySQL 和 Maria DB 两种精度格式了。
但是在我们实际升级到 MariaDB 10.1.9,即当前生产环境 MariaDB 新版本时,依旧碰到了问题。
该问题可由以下步骤触发:
- 上游为10.0.x 老版本或参数设置为 OFF 的新版本,下游为参数设为 ON 的新版本,此时旧表数据能正常同步
- 然后在上游新建了一张有时间精度字段的表, sql 语句随着 QUERY_EVENT 传至下游并在下游执行,此时上游为 MariaDB 格式,而下游为 MySQL 格式
- 上游插入数据,此时下游报错,同步中断。报错 1610。根据官方文档,错误描述为 “Corrupted replication event was detected”。

我们在 MariaDB 官方社区发现了一个与之对应的 issue: MDEV-9560, 而相应的修复代码在这里: 当新版本(10.1)从老版本(10.0)同步带有时间精度的列时,会导致服务奔溃。该版本在 10.0.25 和 10.1.12 开始生效。考虑到目前我们生产环境的新老版本分别是 10.0.10 和 10.1.9, 同步出现问题也就不奇怪了。
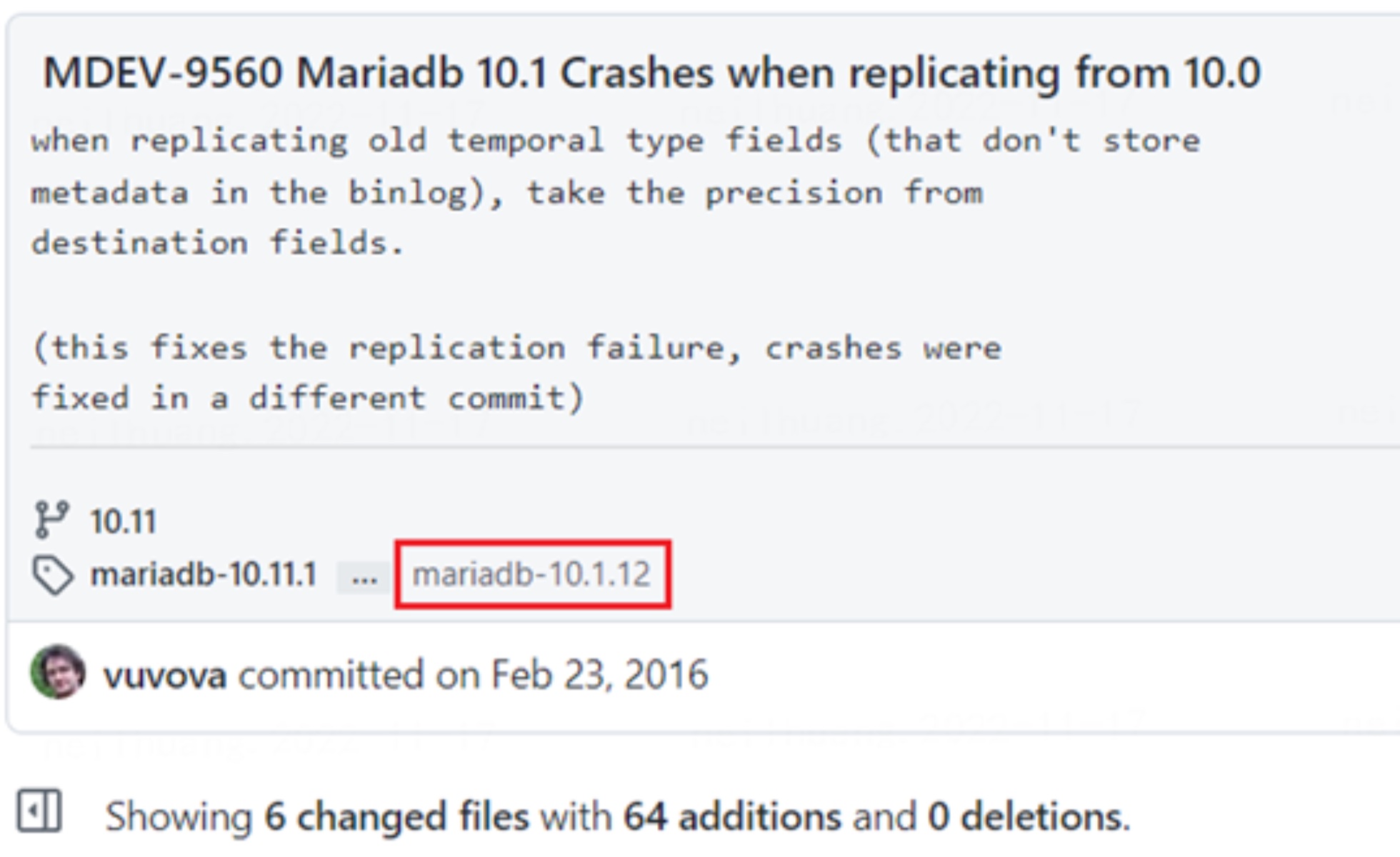
该修复的核心代码在 rpl_utility.cc 中的 create_conversion_table 中。该函数用于将 binlog 中的表结构和表数据转换为一个 tmp_table, 并在后头进行相应的复制操作。
可以看到,若 binlog 中的类型为旧时间版本(可从 TABLE_MAP_EVENT 中获取)并且本地的类型带有精度,则会给 max_length 把本地存储的精度值加给 max_length,额外加一位用于读取 nullbitmap。
注释中解释了该行为的合理性:
因为无法从binlog中获取主节点的时间精度,因此假设主备节点精度是一致的。当没有涉及转换时,该假设是成立的(上下游表结构必然一致)。 因此,如果当此处需要进行转换时,该假设也是成立的。
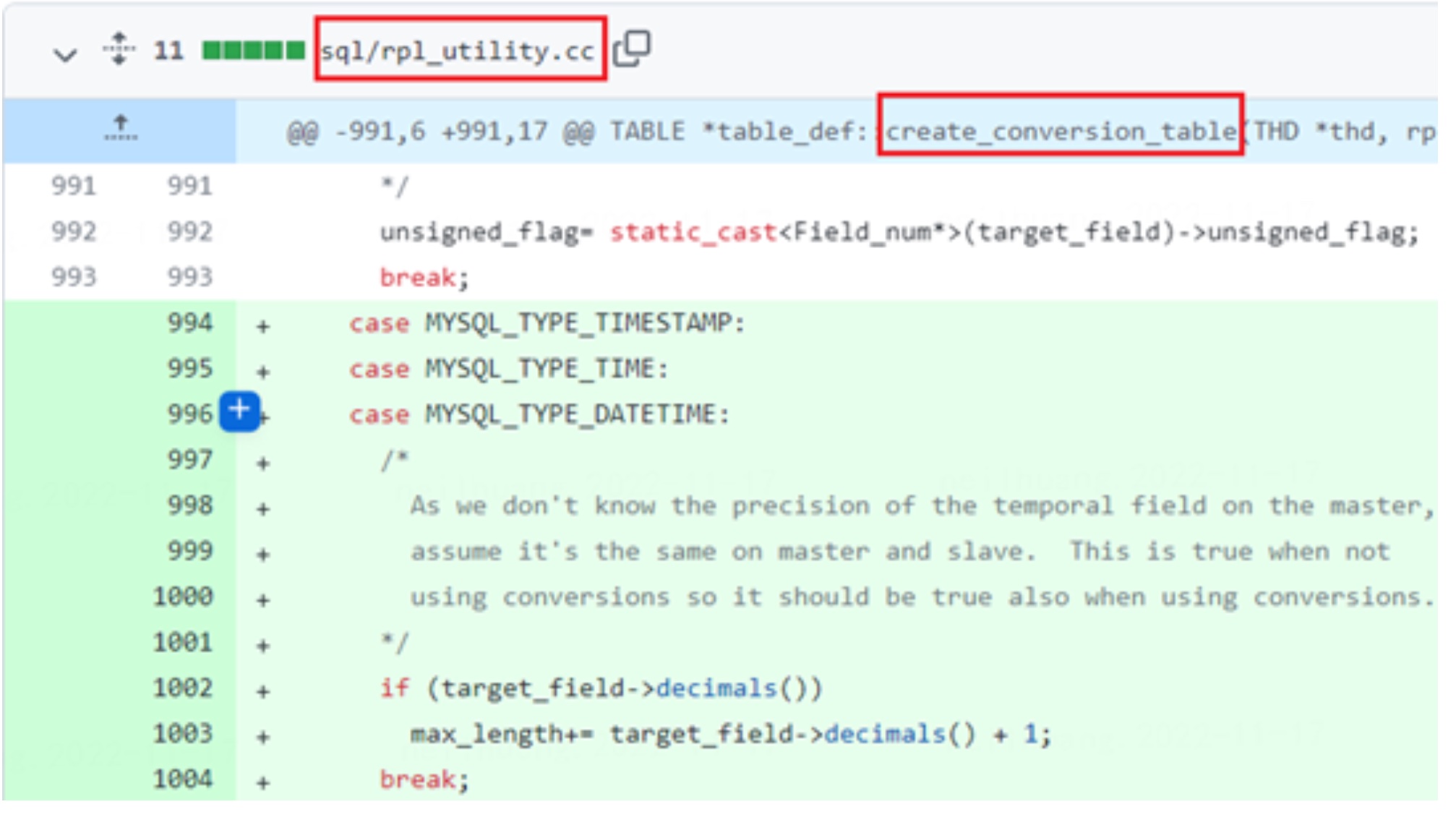
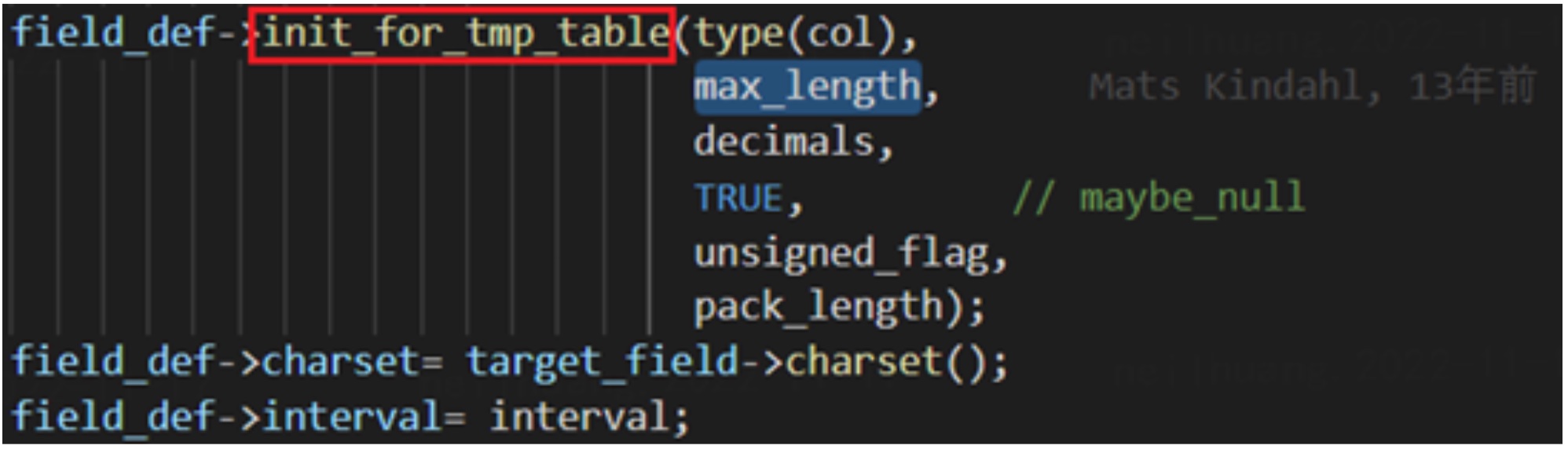
在之后, max_length 会传入 create 的真实过程中并用于指定字段读取长度。
4.8 DM / go-mysql
前文提到 DM 进行数据流转的真实逻辑是把自己伪装成一个备节点,从上游节点出 dump binlog 并进行解析。此处的拉取和解析 binlog 的操作均由第三方包 go-mysql 完成。
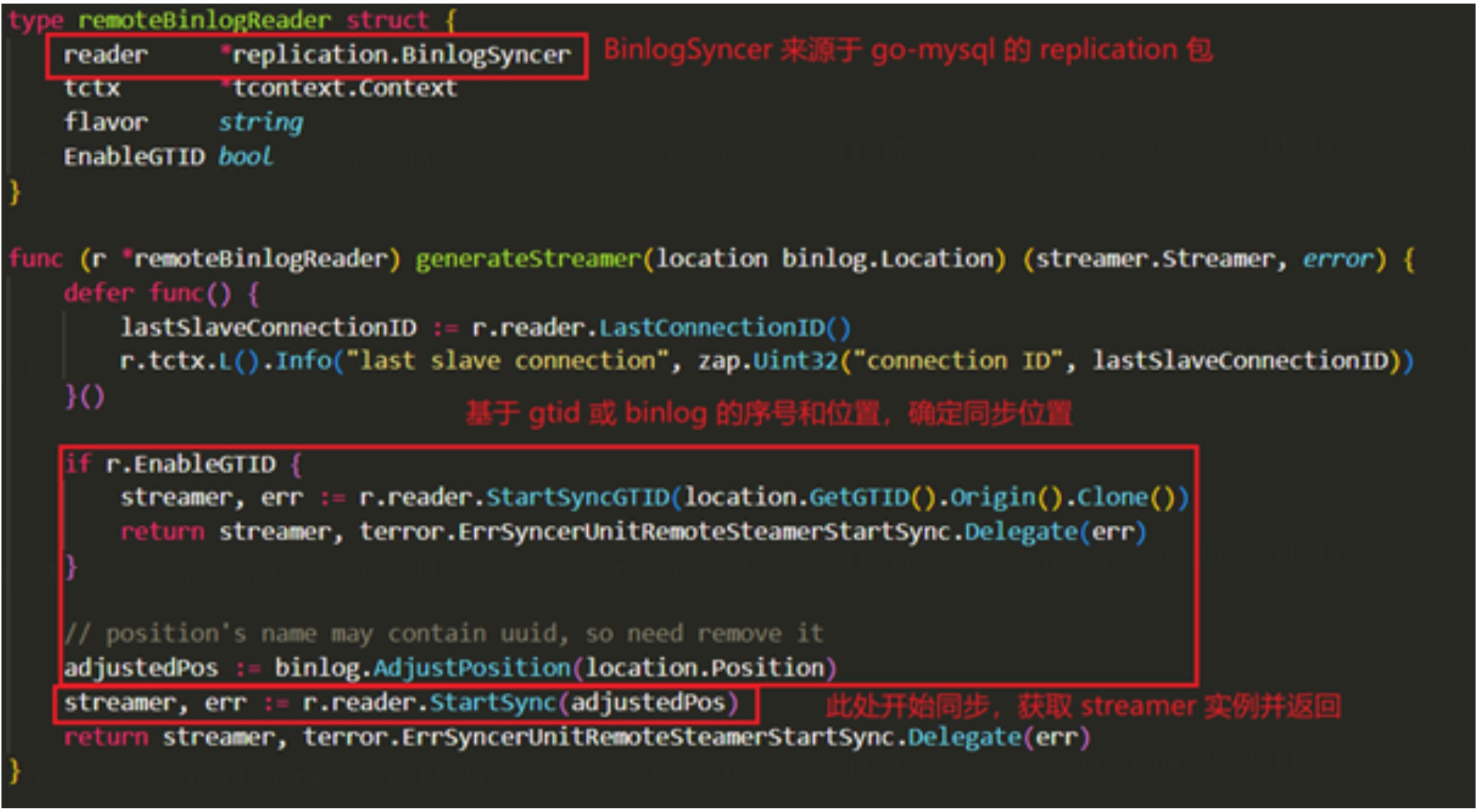
由具体操作流程可知,在 binlog_streamer 初始化时, DM 会初始化一个来源于 go-mysql 的 binlogSyncer 实例,开始从上游同步,包装完成后返回。
PS: DM 可以直接从上游同步(syncer) 或从本地提前拉取的 reply log 同步(relay)。二者类似,以下示例均为 syncer 模式。
因此,想知道真实问题所在,我们只需要关注 go-mysql 的实现即可。
- table_map_event
首先,在处理 TableMapEvent 时, 我们可以发现 go-mysql 获取了类型为 2 的时间类型的源数据, 用于获取精度。因此 go-mysql 是支持 MySQL56 格式的时间精度的。
-
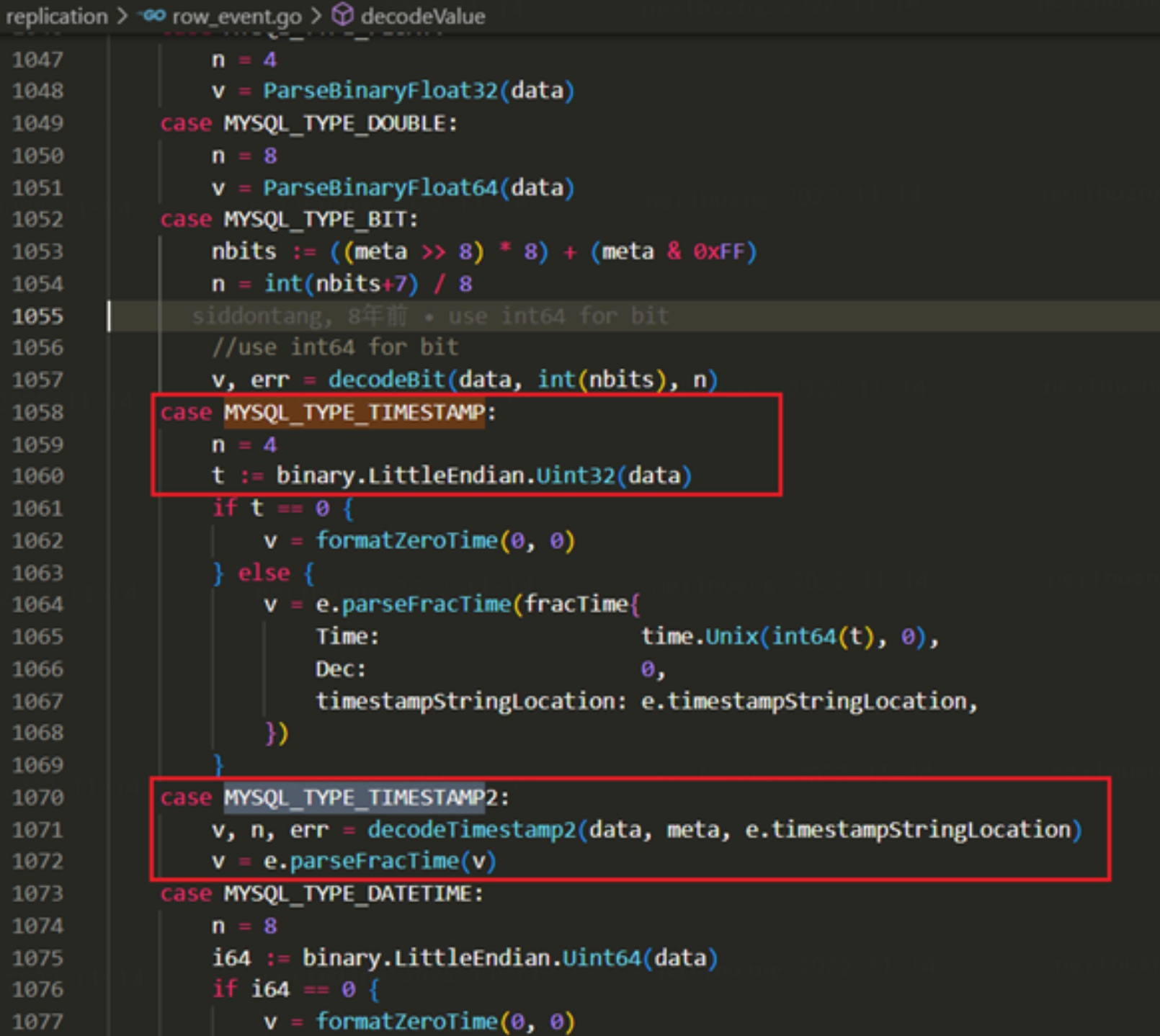
在 decodeValue 函数中, 真实解码 write_row_events 存放的数据时,可以看到对于 MySQL_TYPE_TIMESTAMP 类型的解析, go-mysql 使用了小端序的 Uint32 (即4个字节)读取。此时完全没有考虑精度的可能,因此我们可得出结论, go-mysql 是不支持读取 MariaDB 格式的时间精度的。
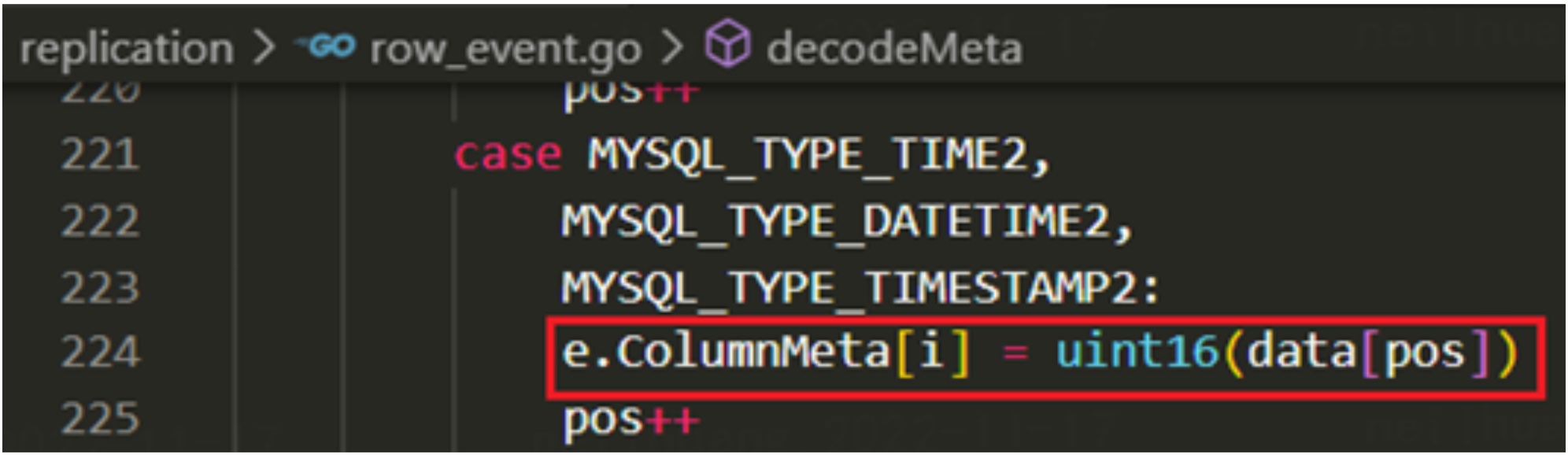
反之对于版本为 2 的类型,go-mysql 会先解码后解析精度,因此该流程是正常的。
-
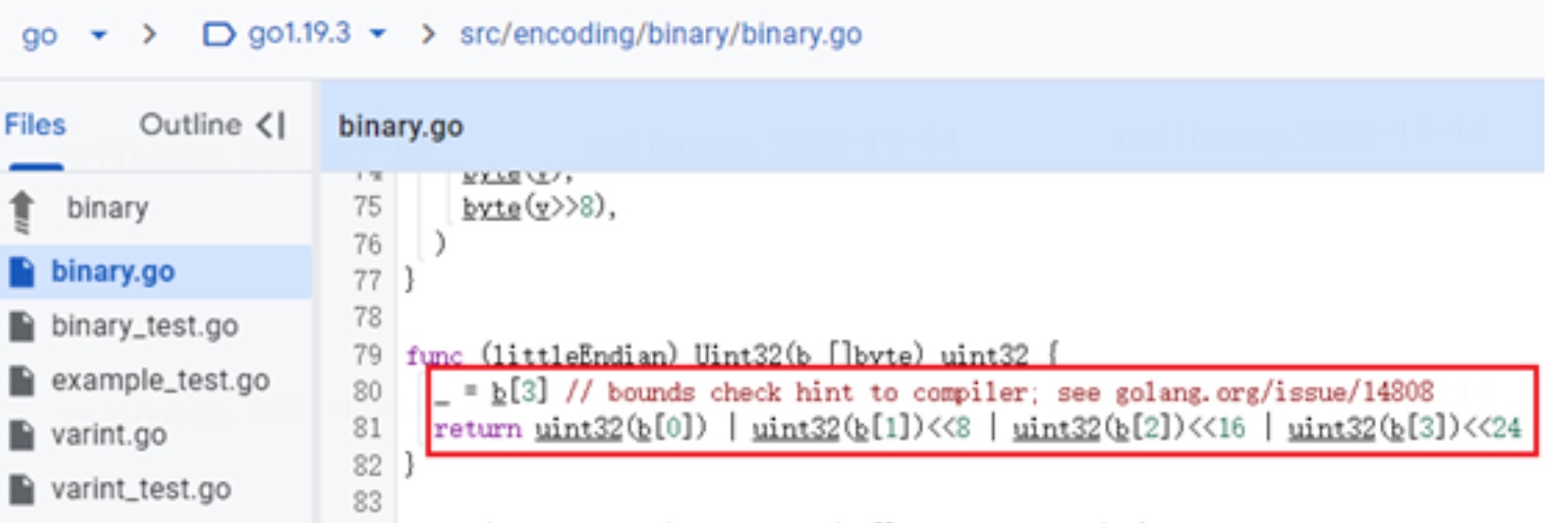
关于 Uint32 函数, go 源码中实现得比较直观。按切片方式获取之后四个字节转换然后求或后返回。但此时该切片中个数不够,导致切片索引读取越界报 panic.
-
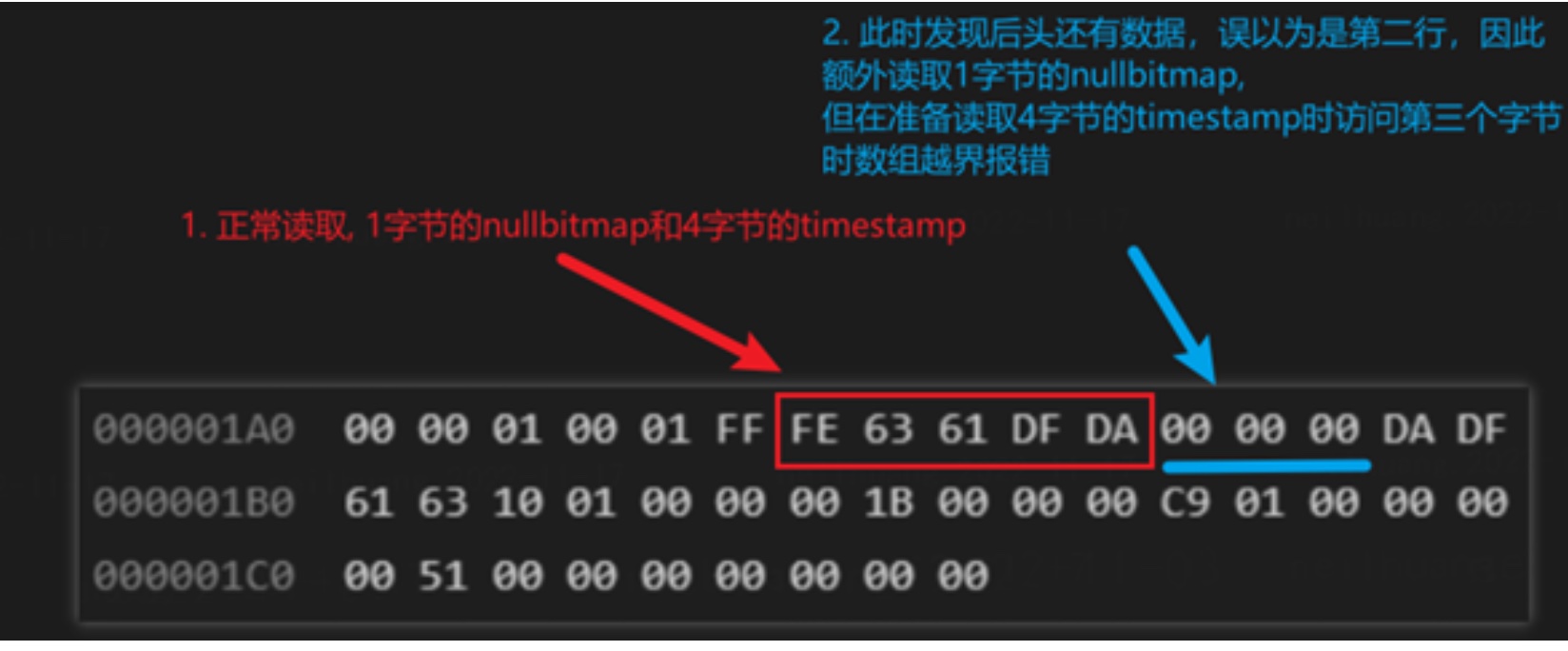
此时我们设置的时间精度为 6,也就意味着该 write_rows_event 中存在有 8 个字节(1 nullbitmap + 4 unix timestamp + 3 frac)。 但在经过一轮循环后(读取5字节), 余下3字节。
此时,go-mysql 误以为是第二行的数据,因此再次读取。读取1字节的 nullbitmap
后,只余下了两字节,但 go-mysql 对余下切片调用 Uint32 函数,于是在读取第四字节时报错。
查看 panic 错误,和我们预想的一致。

- 因此我们得出结论:go-mysql 对于 MariaDB 的时间精度格式不兼容,没有考虑到 WRITE_TABLE_EVENT 中存在精度的可能性,导致了错位的解析并最终报错退出。
5. 解答问题
经过源码解析,我们可以回答第三部分提到的几个问题。
- MySQL/MariaDB 对于 时间精度特性 支持的版本发展历程,包括存储和replication
MariaDB(5.3) 首先支持了时间精度,但对于同步场景欠考虑,于是在 MySQL(5.6) 提供了新的解决方案之后转而在新版本(10.0.4,10.1.2)支持了 MySQL 的实现, 并修正了部分异常场景(10.1.12)。
- MySQL/MariaDB/DM 对于 含有时间精度 Binlog 的解析原理
(一) MySQL: 只支持 MySQL 格式的时间精度格式:从 binlog 中TABLE_MAP_EVENT 中获取类型和精度再进行解析
(二) MariaDB: 支持 MySQL 时间精度格式格式 和 MariaDB 的时间精度格式:若上游为 MariaDB 时间精度格式格式,则会依据本地 frm 文件存储的字段精度再进行解析;若上游为 MySQL 时间精度格式格式,则进行隐式判断后转换再进行解析。
(三) DM(go-mysql): 只支持 MySQL 格式的时间精度格式。在解析 MariaDB 的时间精度格式时,会因为不识别精度导致解析错位,最后导致异常或解析结果错误。而高版本的 mariadb 默认以 MySQL 的时间精度格式生产 binlog,此时 DM 可正常解析。
3. mysql56-temporal-format 参数的含义
MariaDB 于 10.1.2 版本引入该参数。当该参数设置为 ON 时,在 frm 中新建的表会用 MySQL 的时间精度格式存储(即 type2)。同时,生成的 binlog 在 TABLE_MAP_EVENT 中也会用 MySQL 的时间精度格式存储(即 type2), 同时在源数据( metadata )一列附上精度。
当该参数设置为 OFF 时,表结构存储和生成的 binlog 表现与 10.0.x 旧版本一致。
6. 优化方案
结合以上的分析,针对TiDB DM可以做以下几个优化:
- 优雅报错:
查看 go-mysql 代码得知,dm 不兼容时会直接 panic 而非报错的原因是直接调用了 Uint32 访问数组越界,因此,提前比较当前读取位置和数组长度,若有异常报错退出而非 panic 可实现优雅报错。
该优化实现难度低,遇到此问题人工干预操作,但同时,在极端情况下,列字节数巧合对上时能够解析成功不会报错,但此时解析结果是错误的。
如以下例子:
# 上游执行sql 创建表并插入数据
create table test2(ct timestamp(2));
insert into test2(ct) values("2022/11/10 21:12:33.99");
# 查看存入数据
MariaDB [test]> select * from test2;
+------------------------+
| ct |
+------------------------+
| 2022-11-10 21:12:33.99 |
+------------------------+
1 row in set (0.00 sec)
而此时 go-mysql 正常解析, 但输出错误结果:
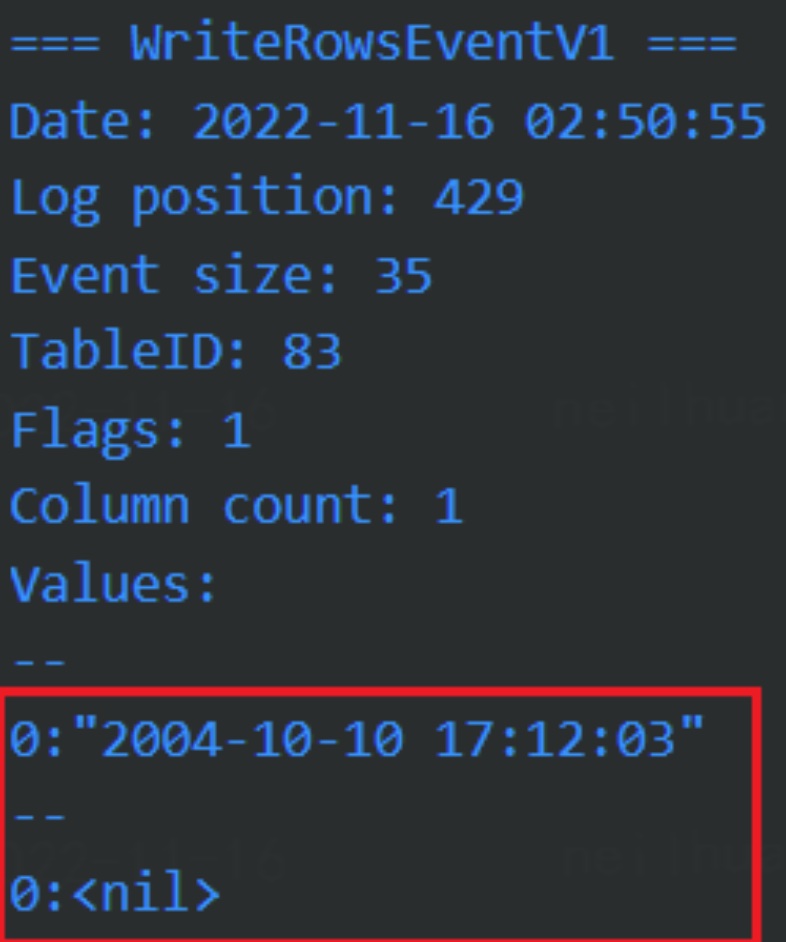
- 库表过滤:
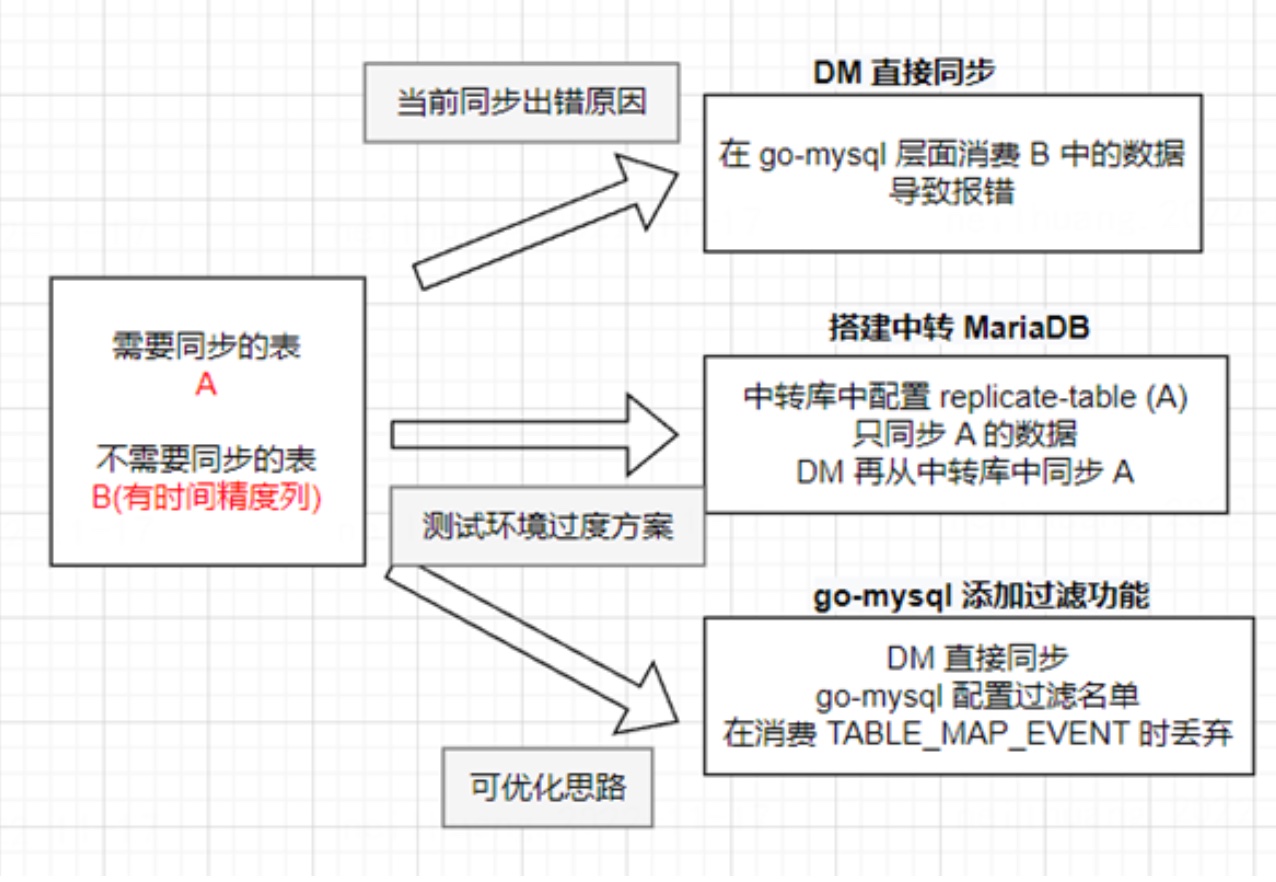
该优化方案来源于之前测试环境的一个过度方案。
MariaDB 主备同步时支持指定 replicate-* 的配置,显式指定需要同步库表的黑白名单。因此我们在测试环境搭建了中转库,使用 中转库先同步所需的表,再搭建DM从中转库中同步。
那么, MariaDB 是如何实现过滤的呢?- 首先,MariaDB 专门设计了一个提案来实现库表过滤,并构造了一个类叫 rpl_filter来实现它。核心在于 db_ok 和 tables_ok,用于过滤库名和表名。
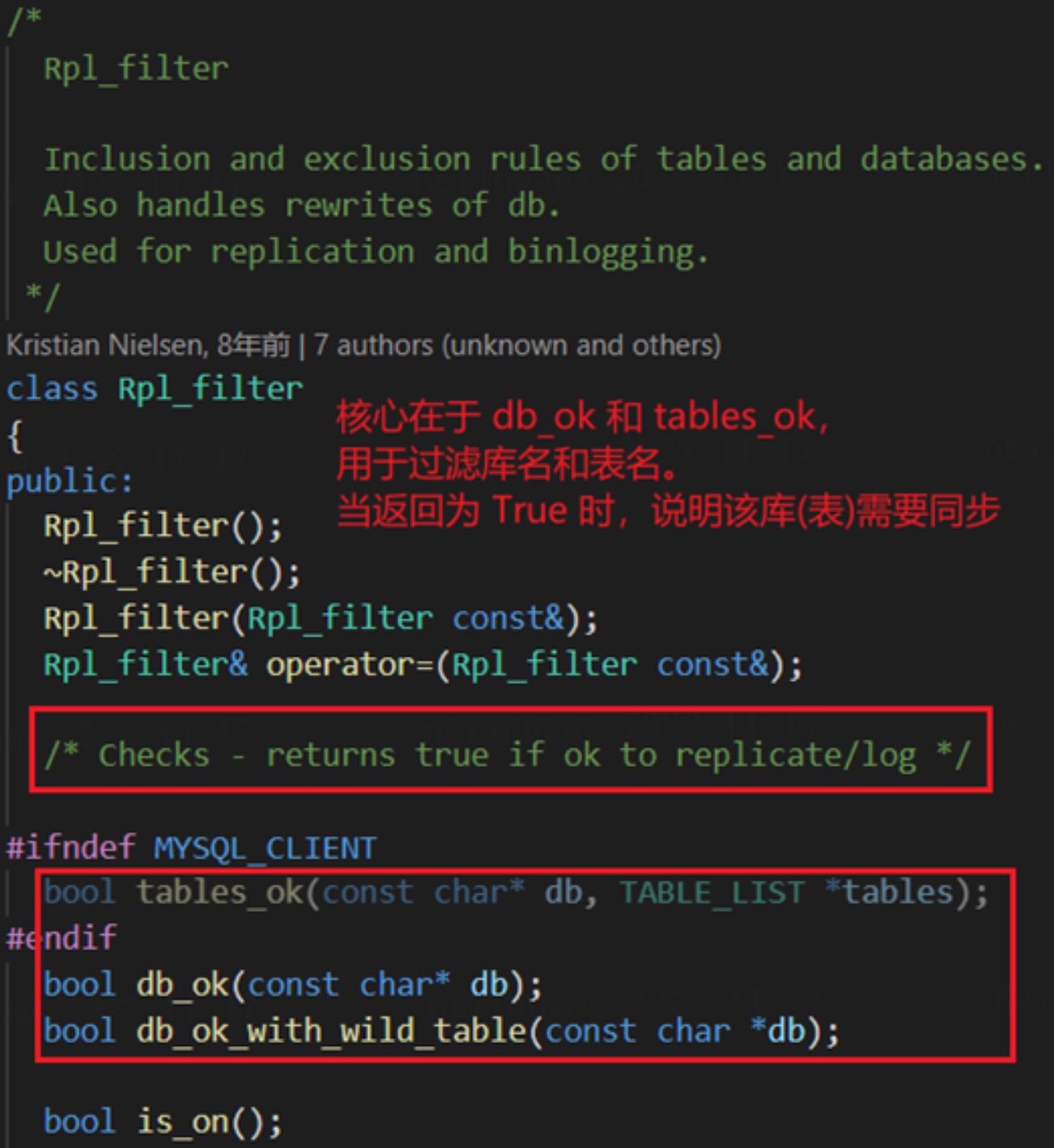
- 首先,MariaDB 专门设计了一个提案来实现库表过滤,并构造了一个类叫 rpl_filter来实现它。核心在于 db_ok 和 tables_ok,用于过滤库名和表名。
- 之后,我们能从源码中找到标识过滤的枚举量:
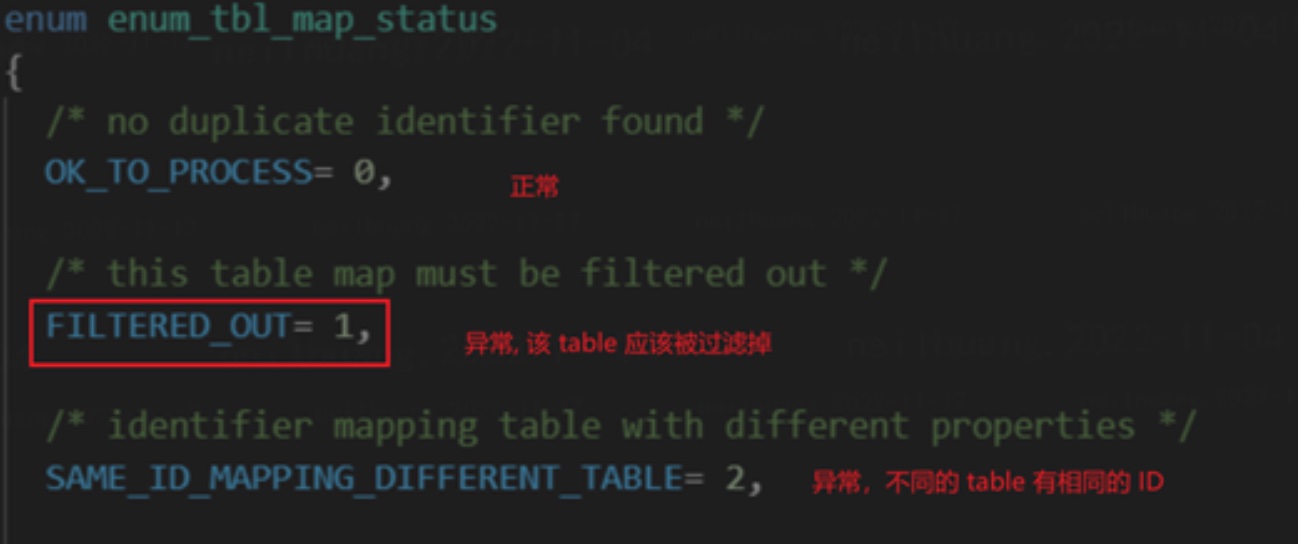
该枚举量在解析 TABLE_MAP_EVENT 时被调用:
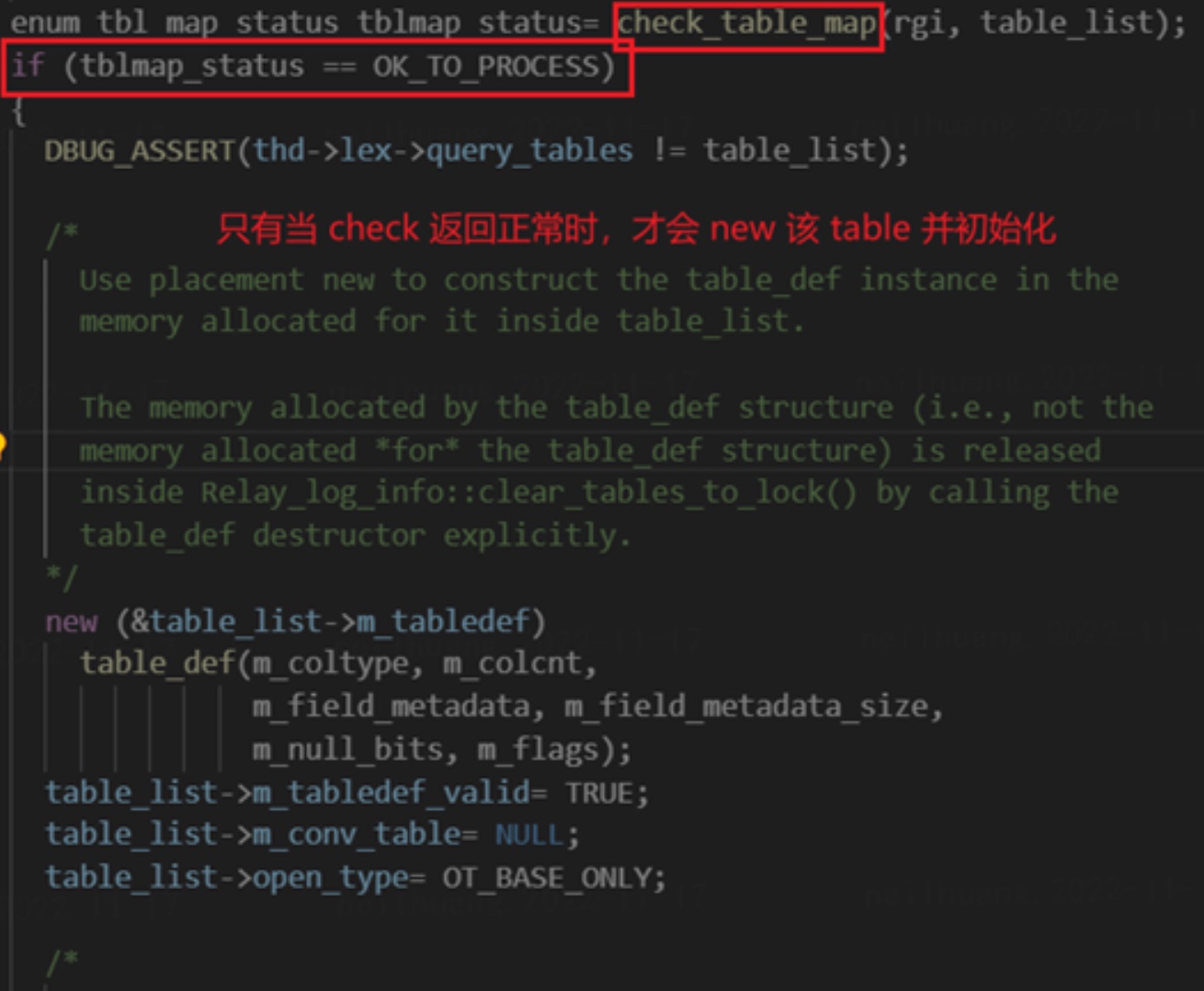
- 那 check_table_map 究竟做了什么呢?
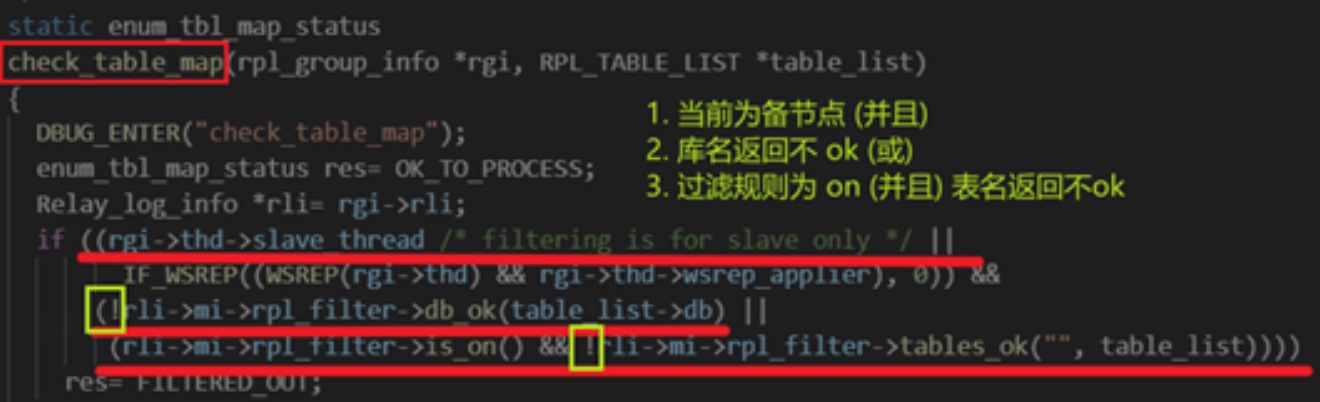
因此,从代码层面可知,MariaDB 的库表过滤是建立在 binlog 消费层面的。 在解析 TABLE_MAP_EVENT 时,根据其中存储的库表名,就能够提前进行过滤并判断是否需要消费之后的 WRITE_ROWS_EVENT。
而与之相对的,go-mysql 并没有提供对应的库表过滤功能,也就导致和 dm 同步不相干的库表也会引发错误。即便 DM 支持过滤,但这并不是在 binlog 消费层面,对于该问题并没有帮助。
因此,我们提出的一个解决方案是,go-mysql 支持库表过滤:参考 mariadb 的 replicate-* 的实现:在 table map event 的时候,把拿出的表标记,当涉及到过滤的表的 ROWS_EVENT_V1 时,不处理直接跳到下一个。
同时我们也能发现,若 go-mysql 能够支持库表过滤,那可以在处理 binlog event 的层面大大加快解析速度,提升整体效率。
如上游源有 100 个表,而我们只需要同步其中一个, 原先 go-mysql 会全量消费 100 个表产生的所有 binlog。而当实现库表过滤后,可以跳掉 99% 不相干的表,大大提升效率。
-
显式转换:
同理,既然我们能够参考 MariaDB 的库表过滤,那是否也能完全实现一个类似的主备同步呢?- 在初始化阶段,传入 dump 拿到的建表语句,解析生成表结构。
- 之后定时消费上游 binlog 中的 alter 语句和 create 语句, 维护自身变化。
- 当检测到 table event 中 column type 分别为新旧版本时,如上游是 TIME 但是下游是 TIME2 时, 自动赋值精度并解析
该实现难度高,但是全流程自动化,能同步有时间精度的表。
-
外部维护:
行内大数据团队 binlog 采数也遇到了类似的问题,其实现方案,可以通过人工干预处理。
- 实现难度中,需人工干预,能同步有时间精度的表
- 添加一个接口,初始化时手动指定有问题库表的时间精度,如 test.test, @1, TIME, 3
- 如上游有变动,优雅报错并暂停,待人工更新后恢复
- binlog 中不存放字段名称,用@指代,需额外处理
对于以上优化思路进行总结:
| 优化思路 | 难度 | 有时间精度的表 | 优势 | 备注 |
|---|---|---|---|---|
| 优雅报错 | 低 | 不可同步 | 不会出现 panic | 同步中断 |
| 库表过滤 | 中 | 不可同步 | 1. 非同步有时间精度表不中断 2. 加快解析效率 | / |
| 显式转换 | 高 | 可同步 | 流程自动化 | / |
| 外部维护 | 低 | 可同步 | 实现简单 | 需人工干预 |
最终我们把整体的问题分析过程、方案详情给到了 PingCAP,并推动优先落地 TiDB DM 的 库表过滤 方案(在 go-mysql 层就直接通过 table map event 来真实过滤库表),该方案带来收益较大(可以过滤非同步表,提升同步效率),开发成本适中,可以作为快速的过渡方案。